Model Serving
The LLMOS platform provides a streamlined way to serve machine learning models using the ModelService resource. This resource offers a user-friendly interface to configure and manage model serving, leveraging the powerful vLLM serving engine. By specifying parameters like the model name, Hugging Face configurations, resource requirements, and more, users can easily set up and deploy models efficiently and at scale.
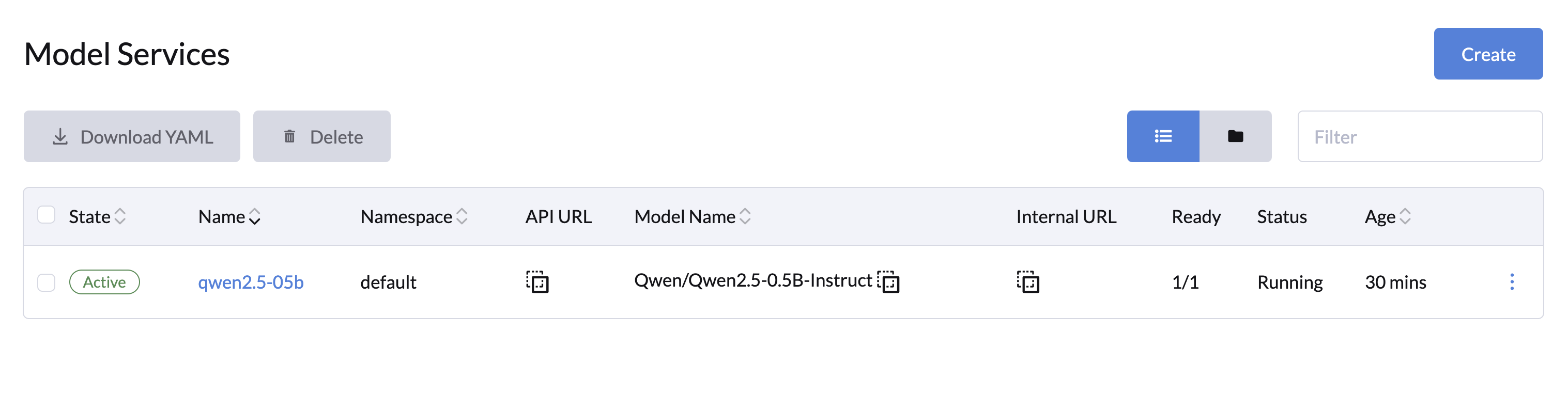
Creating a Model Service
You can create one or more model services from the LLM Management > Model Services page.
General Configuration
- Specify the name and namespace for your model service.
- Enter the model name, either from Hugging Face (e.g.,
Qwen/Qwen2.5-0.5B-Instruct) or a persisted model volume path (e.g.,/root/.cache/huggingface/hub/models--Qwen--Qwen2.5-0.5B-Instruct). - (Optional) Add any additional engine arguments, such as
--dtypeor--max-model-len, in the Arguments field. - (Optional) Add Hugging Face Configuration:
- If the model is only authorized for downloading, select a secret credential that contains the Hugging Face access token.
- Specify a custom Hugging Face Mirror URL if necessary (e.g.,
https://hf-mirror.com/).
- (Optional) Add additional environment variables for the model service in the Environment Variables field.
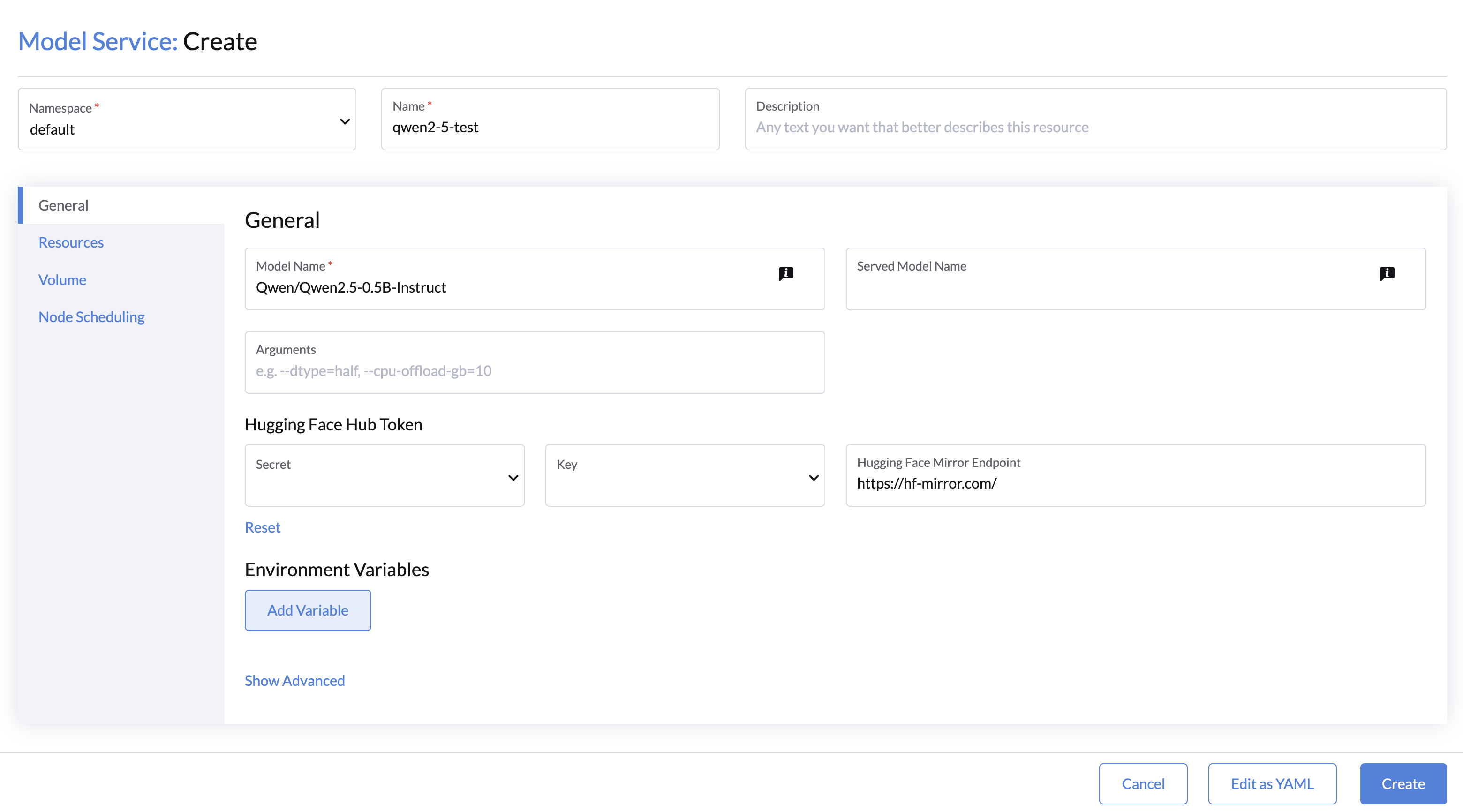
Resource Configuration
- CPU and Memory: Set CPU and memory resources for the model service.
- You may refer to LLM numbers for getting a better understanding of the resources consumed by the model.
- GPU Resources:
- Configure the desired GPU and Runtime Class(default to nvidia).
- A minimum of 1 GPU is required for the model service with the default
vllm-openaiimage.
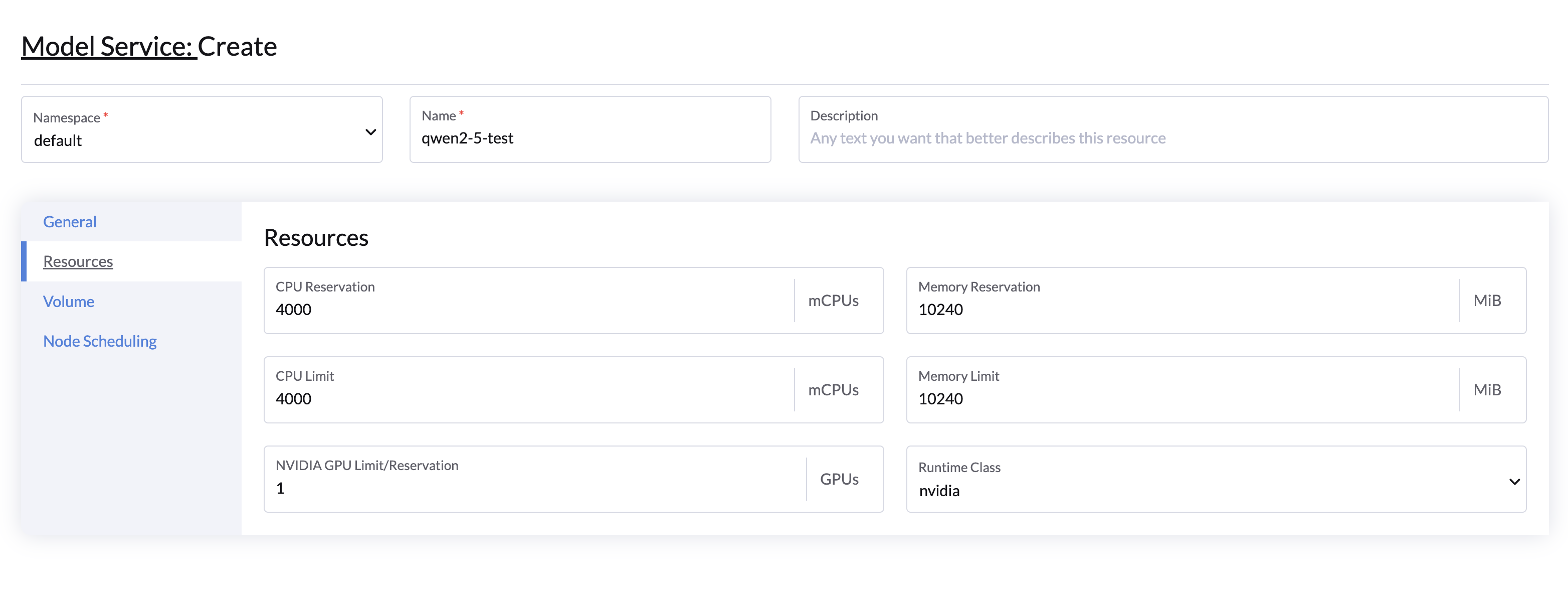
Volumes
- Persistent Volume: A default persistent volume is mounted to
/root/.cache/huggingface/hubto store downloaded model files.- (Optional)You can add an existing volume that contains the model files to skip the download process using the Add Volume button.
- (Optional)You can add a shared volume(with StorageClass support ReadWriteMany mode) to share model files across multiple model services.
- Shared Memory Allocation: Mount an
emptyDirvolume to/dev/shmwith Medium set to Memory. This creates a temporary in-memory filesystem, ideal for PyTorch tensor parallel inference, which uses shared memory between processes.- If not enabled, the model service will use the default shared memory(shm) size of 64 MiB.
Node Scheduling
You can specify node constraints for scheduling your model service using node labels, or leave it as default to run on any available node.
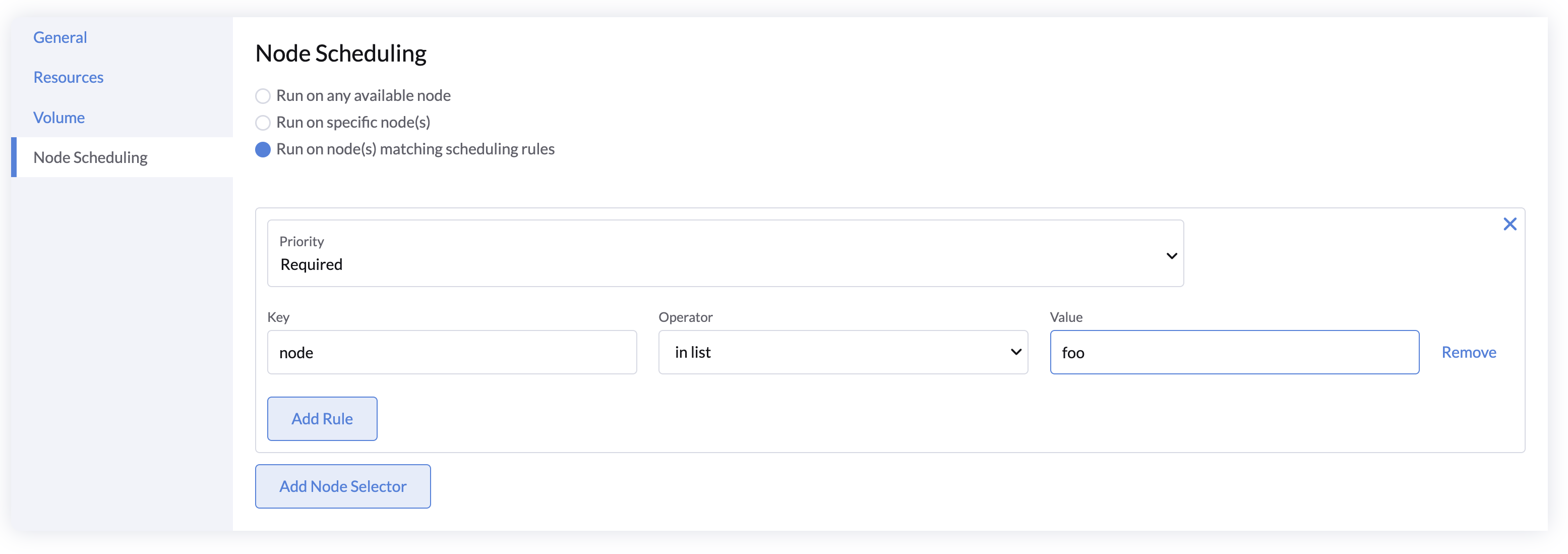
For more details, refer to the Kubernetes Node Affinity Documentation.
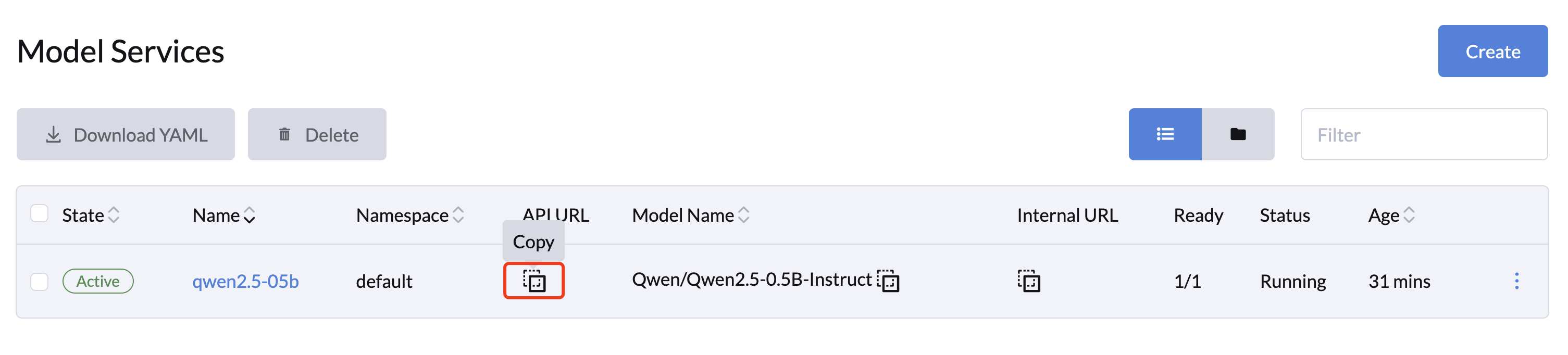
Accessing Model Service APIs
The Model Service exposes a list of RESTful APIs compatible with OpenAI's API at the /v1 path. You can get the model API URL by clicking the Copy button of the selected model.
API Endpoints
| Route Path | Methods | Description |
|---|---|---|
/v1/chat/completions | POST | Perform chat completions using the model service. |
/v1/completions | POST | Perform standard completions using the model service. |
/v1/embeddings | POST | Generate embeddings using the model service. |
/v1/models | GET | List all available models. |
/health | GET | Check the health of the model service HTTP server. |
/tokenize | POST | Tokenize text using the running model service. |
/detokenize | POST | Detokenize tokens using the running model service. |
/openapi.json | GET, HEAD | Get the OpenAPI JSON specification for the model service. |
API Usage Examples
The LLMOS API token can be obtained from the API Keys page.
cURL Example
export LLMOS_API_KEY=myapikey
export API_BASE=192.168.31.100:8443/api/v1/namespaces/default/services/modelservice-qwen2:http/proxy/v1
curl -k -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LLMOS_API_KEY" \
-d '{
"model": "Qwen/Qwen2.5-0.5B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Say this is a test"
}
],
"temperature": 0.9
}' \
$API_BASE/chat/completions
Response Example:
{
"id":"chat-efffa70236bd4edda7e5420349339d45",
"object":"chat.completion",
"created":1727267645,
"model":"Qwen/Qwen2.5-0.5B-Instruct",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"Yes, it is a test."
},
"logprobs":null,
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":24,
"total_tokens":32,
"completion_tokens":8
}
}
Python Example
Since the API is compatible with OpenAI, you can use it as a drop-in replacement for OpenAI-based applications.
from openai import OpenAI
import httpx
# Set up API key and base URL
openai_api_key = "llmos-5frck:xxxxxxxxxg79c9p5"
openai_api_base = "https://192.168.31.100:8443/api/v1/namespaces/default/services/modelservice-qwen2:http/proxy/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
http_client=httpx.Client(verify=False), # Disable SSL verification or use a custom CA bundle.
)
completion = client.chat.completions.create(
model="Qwen/Qwen2.5-0.5B-Instruct",
messages=[{"role": "user", "content": "How do I output all files in a directory using Python?"}]
)
print(completion.choices[0].message.content)
Notebooks Interaction
You can also interact with model services using the Notebooks, which allows you to explore the model’s capabilities more interactively using HTML, graphs, and more (e.g., using a Jupyter Notebook as below).
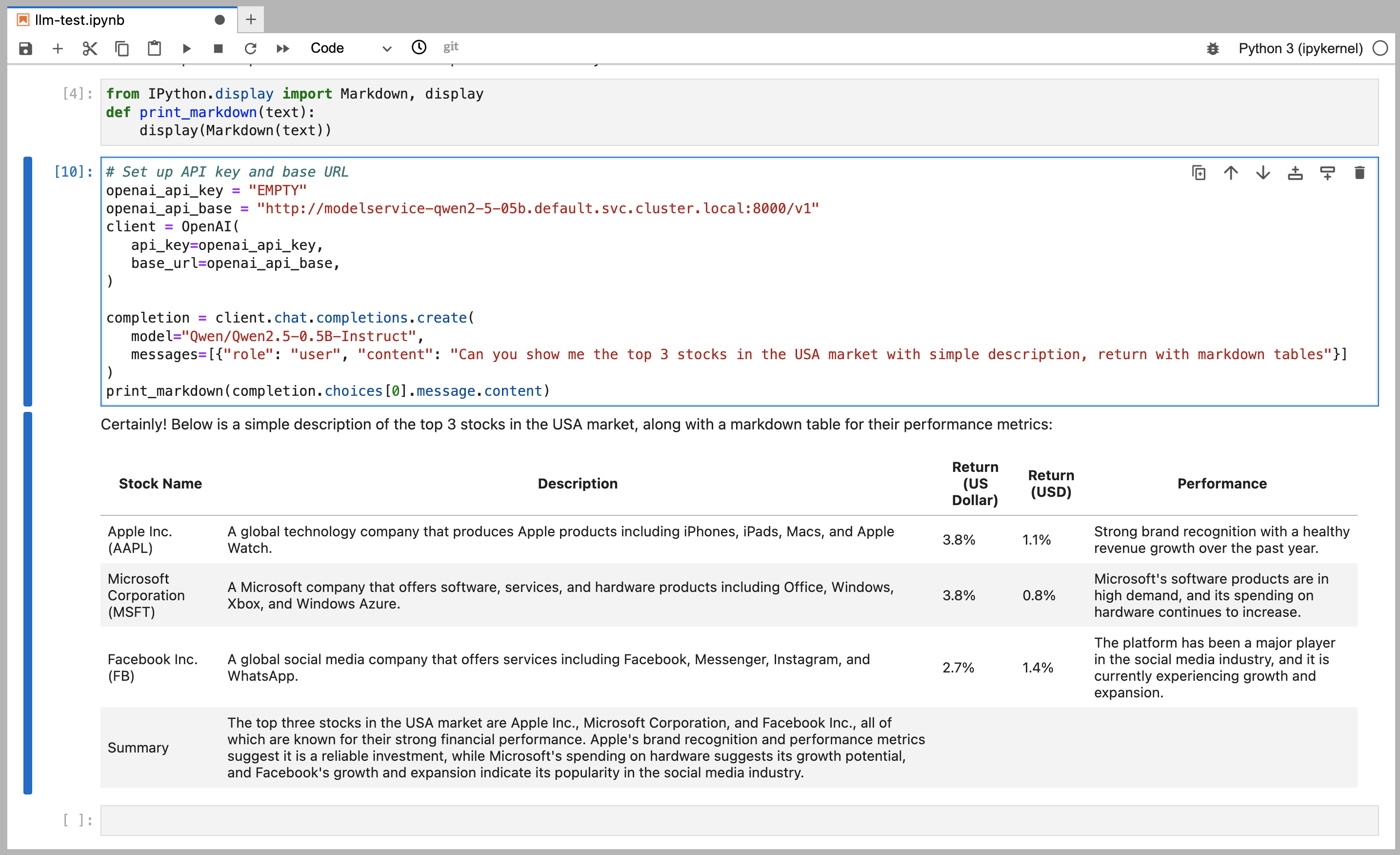
Within your LLMOS cluster, you can connect to the model service using its internal DNS name.
To get the internal DNS name, Click the Copy Internal URL button of the model service.
Adding a HuggingFace Token
If the model is authorized for downloading, you will need to add a HuggingFace token when creating the model service. To add a new HuggingFace token:
- Go to the Advanced > Secrets page and click the Create button
- Select the Opaque type.
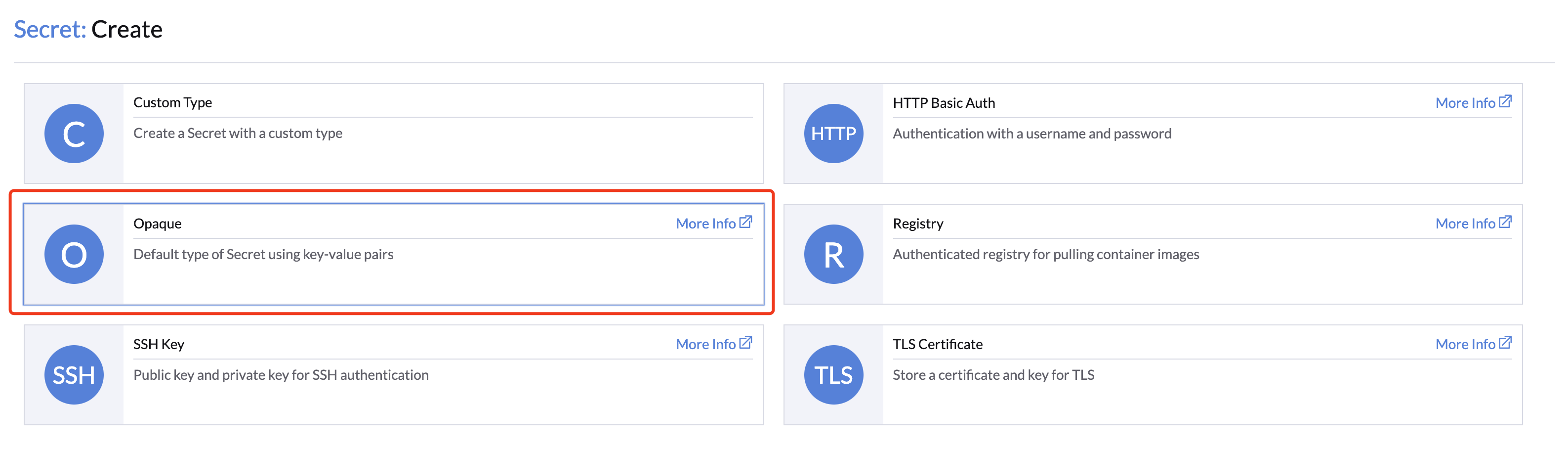
- Select the Namespace and specify a meaningful Name.
- Specify the key e.g,
token, and the value as your HuggingFace token.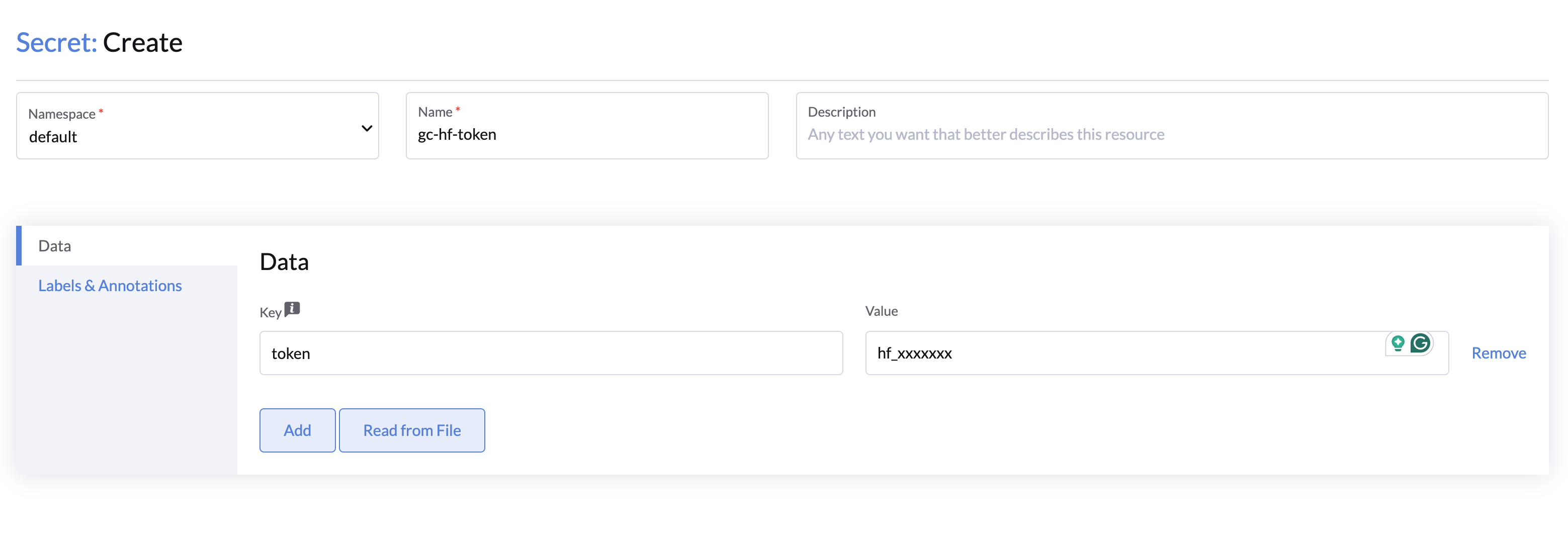
- Click Create to save the secret. And you should see selected secret when creating the model service within the same namespace.