Machine Learning Clusters
A Machine Learning (ML) Cluster provides a distributed computing environment for running machine learning workloads. Built on top of Ray, a unified framework for scaling AI and Python applications, it provides a distributed runtime, parallel processing, and a suite of AI libraries to accelerate your machine learning tasks.
ML Clusters simplify the integration and deployment of Ray clusters with existing cluster tools, such as monitoring, logging, and GPU accelerators. This enables you to effortlessly manage both individual and end-to-end machine learning workflows, leveraging the following features:
- Unified Dashboard: Monitor and debug ML clusters, applications, and tasks from a single interface.
- Unified API: Run ML workloads on independent or shared ML clusters with a consistent API.
- Scalable Libraries: Access Ray libraries for common ML tasks, including data preprocessing, distributed training, hyperparameter tuning, reinforcement learning, and model serving.
- Pythonic Distributed Computing: Utilize distributed computing primitives to parallelize and scale Python applications.
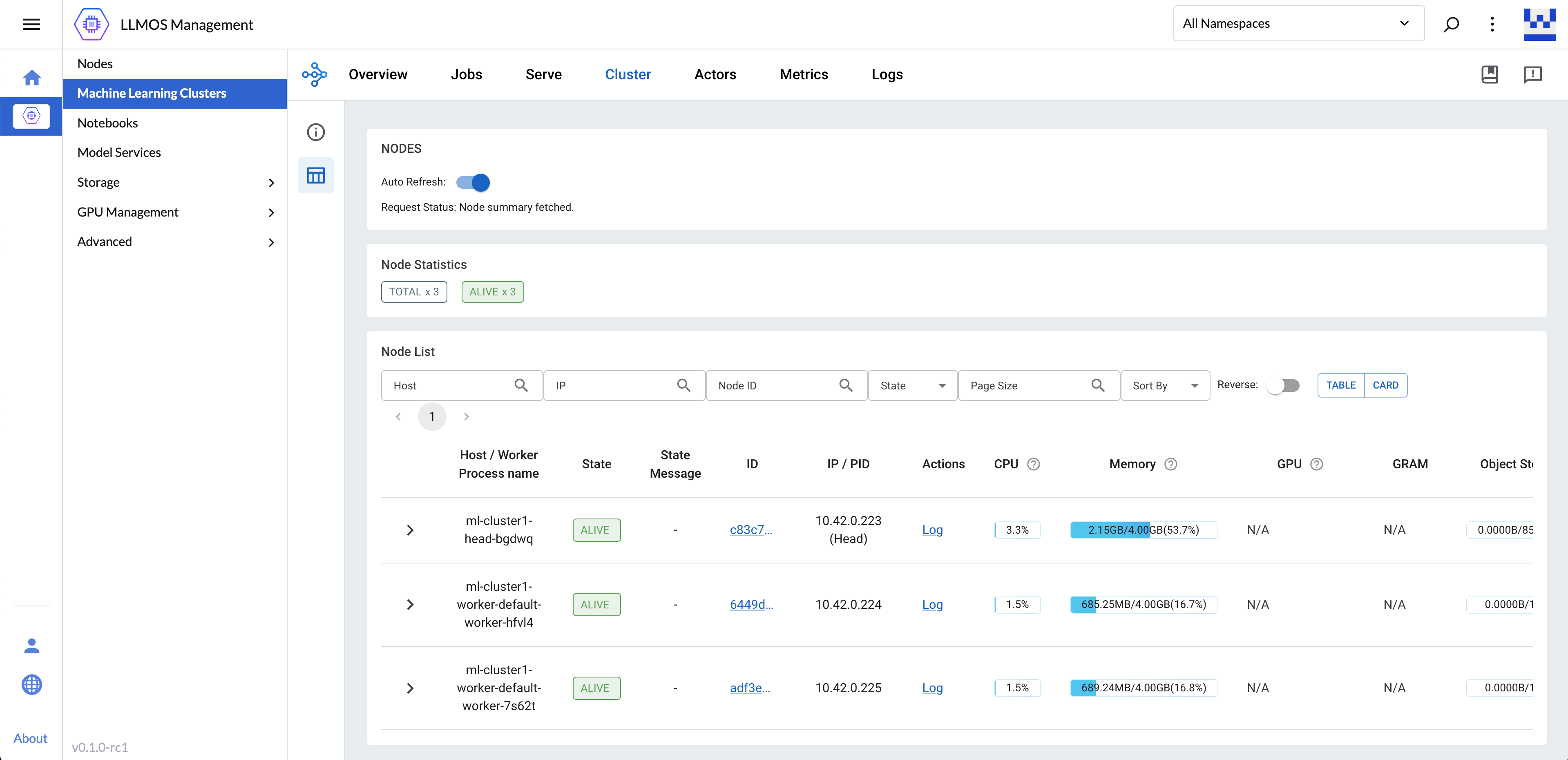
Create a Machine Learning Cluster
ML Clusters will only support KubeRay CRDs starts from v1 version.
To create a machine learning cluster, navigate to the LLMOS Management > Machine Learning Clusters page and click Create.
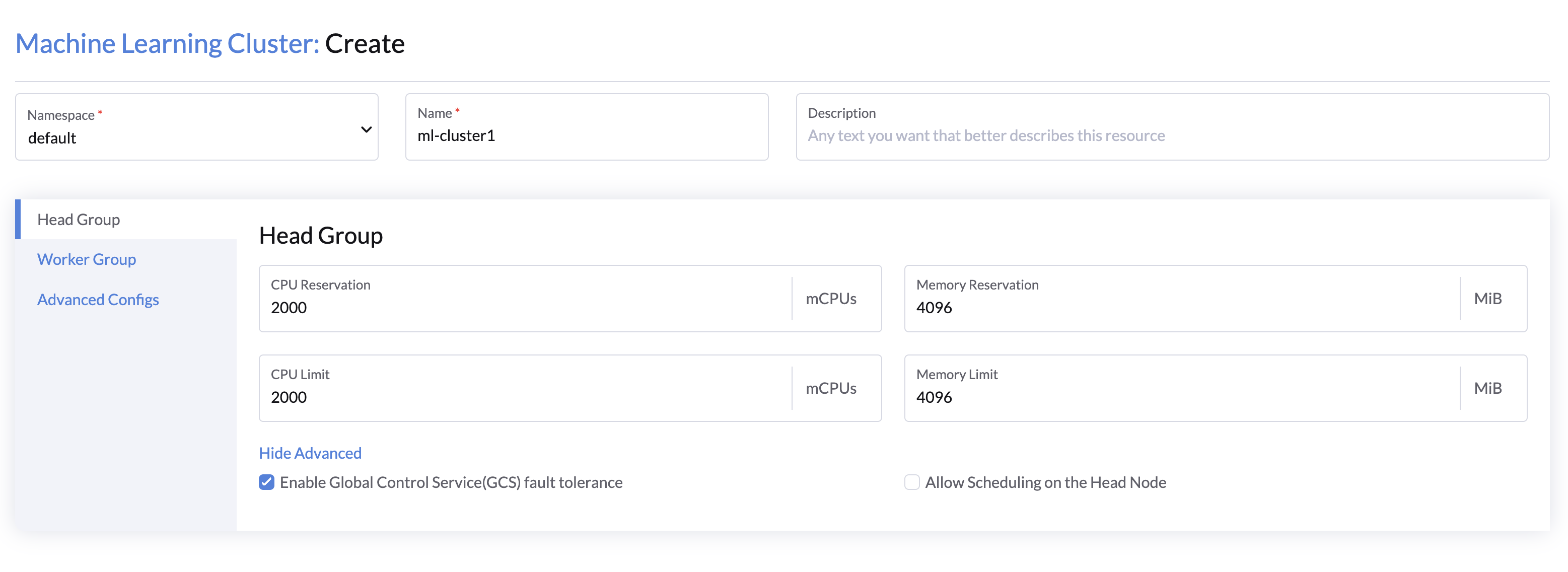
Head Group Configs
- Specify the cluster name, and select the desired namespace.
- Config the CPU and memory resources for the head node(default: 2 vCPU, 4 GB).
- (Optional) Click Show Advanced to configure cluster advanced options:
- Select Enable GCS fault tolerance to provides automatic cluster-level metadata recovery in the event of head node failures.(default: Enabled)
- Select Allow Scheduling on Head Node to allow Ray tasks to run on the head node. (disabled by default, and you must increase the head node resources to support the task)
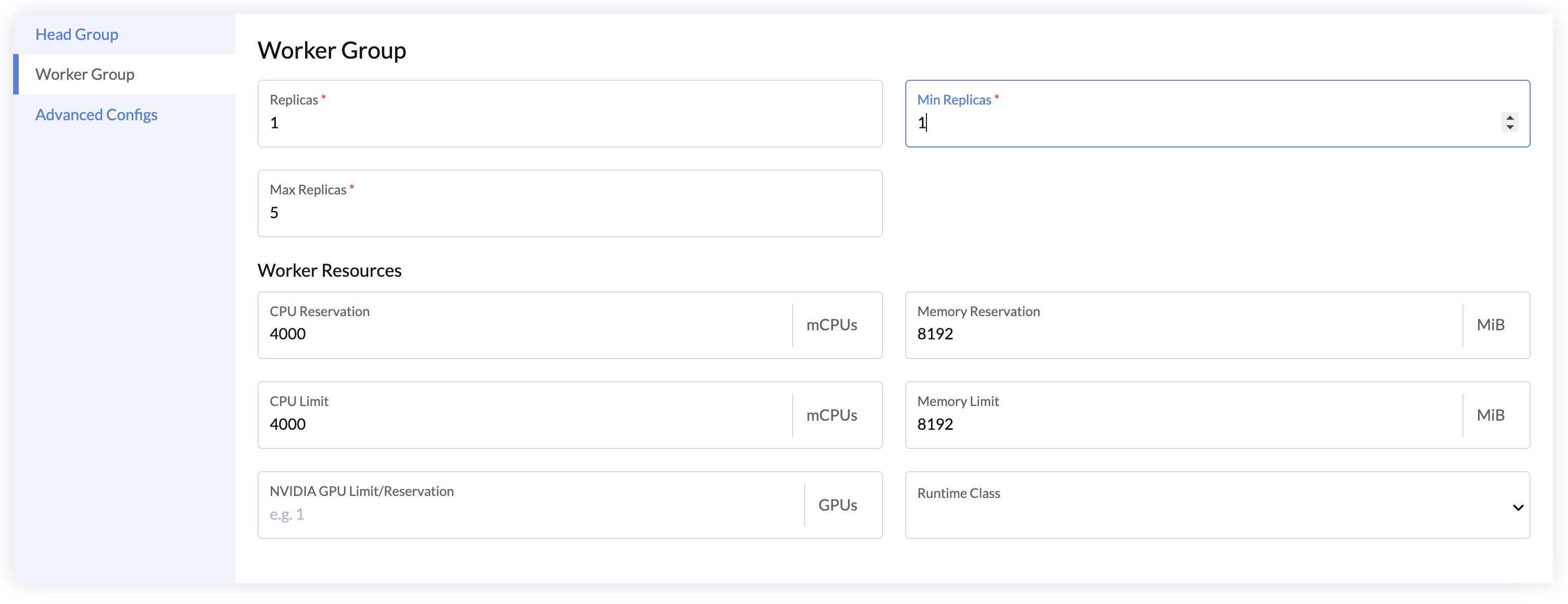
Worker Group Configs
Worker group is a set of worker nodes connected to the head node with same resource configurations. The auto-scale capability can help to save resources by autoscale up and down nodes according to the resources requested by applications running on the cluster.
- Use Replicas to specify the default number of worker nodes on start.
- Configure the Minimum Replicas and Maximum Replicas to set the auto-scale range.
- Specify the CPU and Memory resources for each worker node(default: 4 vCPU, 8 GB).
- Add GPU resources to enable GPU acceleration(only support NVIDIA GPUs for now).
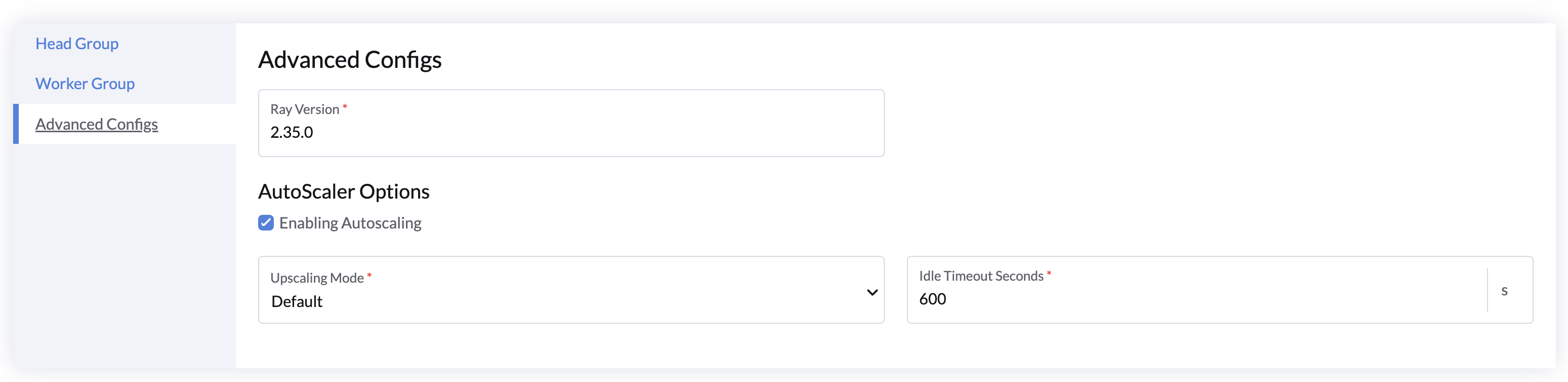
Advanced Configs
- Config the Ray version if you want to use a specific Ray version.
- Auto-Scale Options:
- Check Enabling Autoscaling to enable or disable auto-scaling for the worker group.
- Specify the Idle Timeout in seconds to auto-scale down the worker nodes to minimum replicas when there are no tasks running.
User Guide
Once the cluster is created, you can use the Ray client to connect to the cluster and run your ML workloads at scale.
Setup Ray Client
First, go to your Python project and install the Ray client via:
pip install -U "ray"
If needed, see the Ray installation guide for more details on installing Ray.
Submitting a Ray Job
To run a Ray Job, we also need to be able to send HTTP requests to a Ray Cluster. Let's start with a sample script that can be run locally. The following script uses Ray APIs to submit a task and print its return value:
# script.py
import ray
@ray.remote
def hello_world():
return "hello world"
ray.init()
print(ray.get(hello_world.remote()))
Run the script locally to verify that it works:
python script.py
2024-09-28 22:46:21,735 INFO worker.py:1777 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
hello world
Now let's submit a job to the remote ML cluster using the Python SDK.
The LLMOS API token can be obtained from the API Keys page.
# ray-job.py
from ray.job_submission import JobSubmissionClient, JobStatus
import time
client = JobSubmissionClient(
address="https://localhost:8005/api/v1/namespaces/default/services/http:ml-cluster1-head-svc:dashboard/proxy/", # Replace the url with your ML cluster's endpoint url
headers={"Authorization": "Bearer llmos-qcmqf:xxxxxxxxxxxxxxp4bgq"}, # Replace with your LLMOS API token
verify=False # Disable SSL verification or use a custom CA certificate
)
job_id = client.submit_job(
# Entrypoint shell command to execute
entrypoint="python script.py",
# Path to the local directory that contains the script.py file
runtime_env={"working_dir": "./"}
)
print(job_id)
def wait_until_status(job_id, status_to_wait_for, timeout_seconds=5):
start = time.time()
while time.time() - start <= timeout_seconds:
status = client.get_job_status(job_id)
print(f"status: {status}")
if status in status_to_wait_for:
break
time.sleep(1)
wait_until_status(job_id, {JobStatus.SUCCEEDED, JobStatus.STOPPED, JobStatus.FAILED})
logs = client.get_job_logs(job_id)
print(logs)
The JobSubmissionClient submits the job to the Ray cluster and returns the job ID. The job ID can be used to check the status of the job and retrieve its logs.
python rayjob.py
2024-09-28 22:57:49,615 INFO dashboard_sdk.py:338 -- Uploading package gcs://_ray_pkg_aee80db9018e46d7.zip.
2024-09-28 22:57:49,615 INFO packaging.py:531 -- Creating a file package for local directory './'.
raysubmit_5XExd25xnNqfYSYK
status: PENDING
status: RUNNING
status: RUNNING
status: SUCCEEDED
2024-09-28 07:58:30,120 INFO job_manager.py:527 -- Runtime env is setting up.
2024-09-28 07:58:31,288 INFO worker.py:1458 -- Using address 10.42.0.223:6379 set in the environment variable RAY_ADDRESS
2024-09-28 07:58:31,289 INFO worker.py:1598 -- Connecting to existing Ray cluster at address: 10.42.0.223:6379...
2024-09-28 07:58:31,301 INFO worker.py:1774 -- Connected to Ray cluster. View the dashboard at 10.42.0.223:8265
hello world
You can also check the job status and logs in the ML cluster dashboard.
More Examples
In above, we have shown how to submit a simple job to a remote ML cluster. You can also run more advanced End-to-End ML workflows utilizing the Ray AI libraries. Here are some examples for reference: