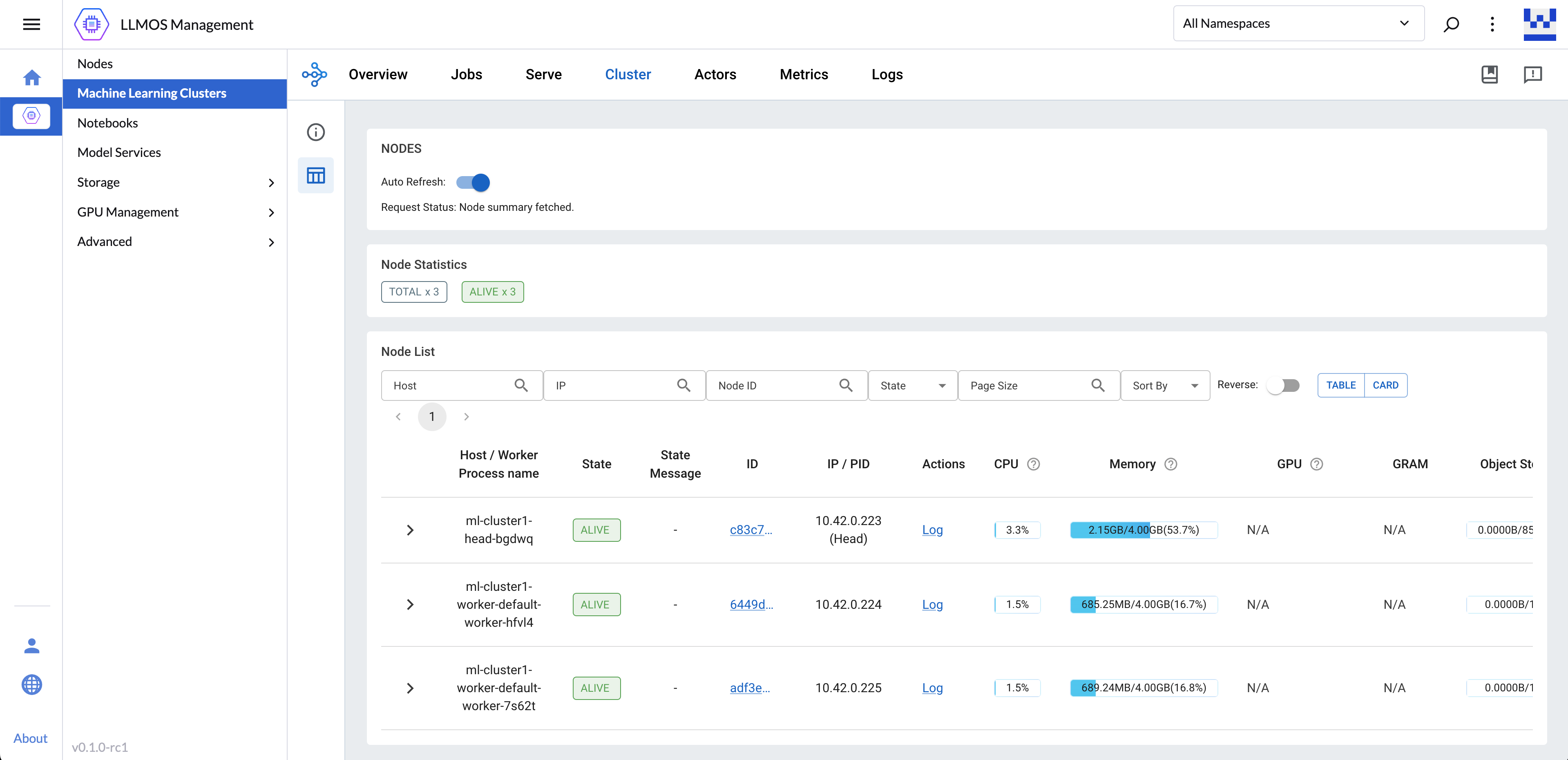
机器学习集群
机器学习集群(ML Cluster)提供了一个分布式计算环境,用于运行机器学习工作负载。该集群基于 Ray 构建,Ray 是一个用于扩展 AI 和 Python 应用程序的统一框架,提供分布式运行时、并行处理以及一套 AI 库,以加速您的机器学习任务。
机器学习集群简化了 Ray 集群与现有集群工具(如监控、日志记录和 GPU 加速器)的集成和部署。这使您能够轻松管理单个和端到端的机器学习工作流程,利用以下功能:
- 统一仪表板: 从统一的界面监控和调试机器学习集群、应用程序和任务。
- 统一 API: 使用一致的 API 在独立或共享的机器学习集群上运行 ML 工作负载。
- 可扩展库: 访问 Ray 库以处理常见 ML 任务,包括数据预处理、分布式训练、超参数调整、强化学习和模型服务。
- Python 风格的分布式计算: 利用分布式计算原语并行化和扩展 Python 应用程序。
创建机器学习集群
机器学习集群仅支持从 v1 版本开始的 KubeRay CRD。
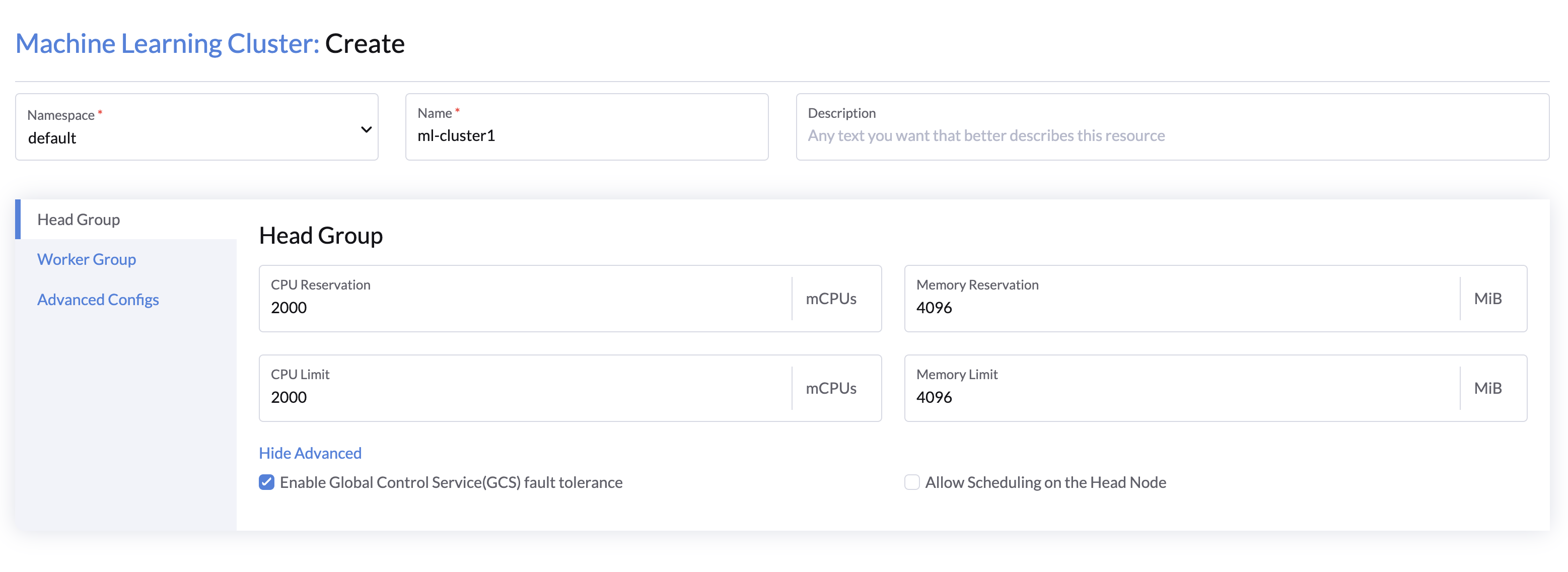
要创建机器学习集群,请导航到 LLMOS 管理 > 机器学习集群 页面并点击 创建。
Head 组配置
- 指定集群名称,并选择所需的命名空间。
- 配置头节点的 CPU 和内存资源(默认:2 vCPU,4 GB)。
- (可选)点击显示高级配置集群的高级选项:
- 选择 启用 GCS 故障容忍,在头节点故障时提供自动集群级元数据恢复。(默认:启用)
- 选择允许在头节点调度,允许 Ray 任务在头节点上运行。(默认禁用,您必须增加头节点资源以支持任务)
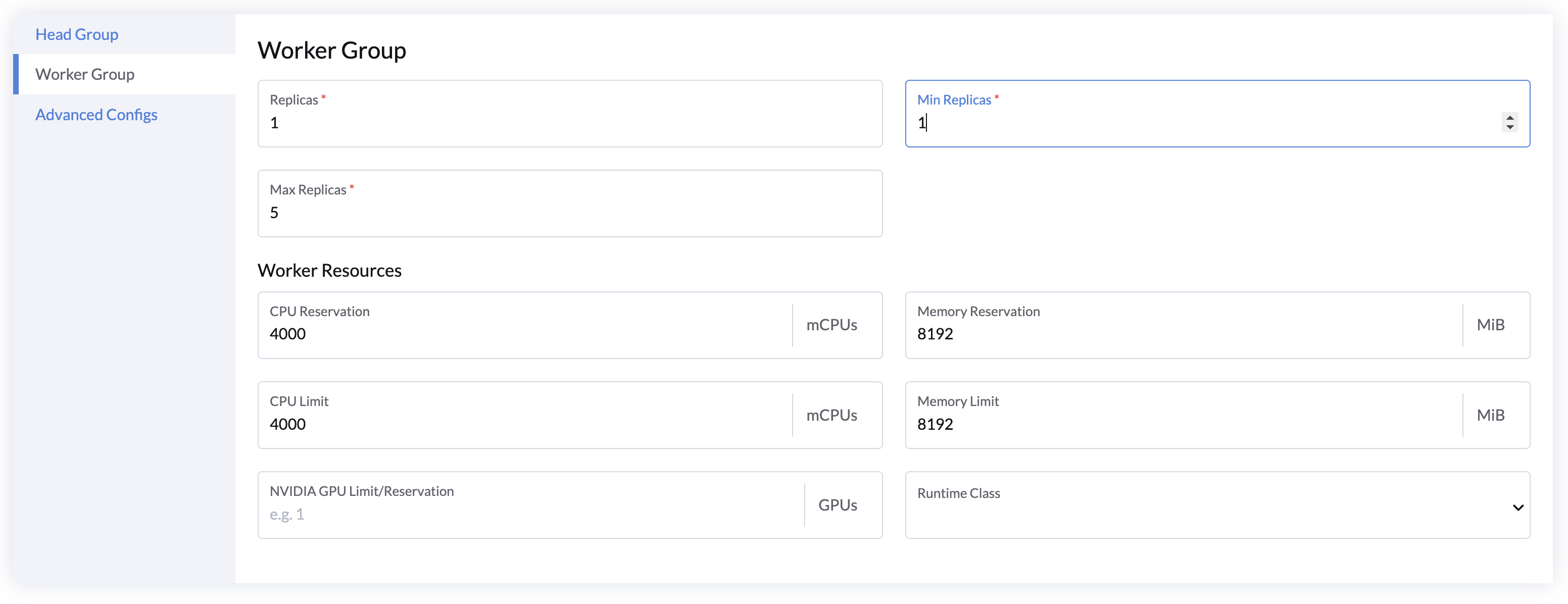
Worker 组配置
工作组是一组与头节点连接并在工作组内使用相同资源配置的工作节点。自动缩放功能可以帮助用户通过根据在集群上运行的应用程序请求的资源自动增加和减少节点来节省资源。
- 使用副本 指定启动时的默认工作节点数量。
- 配置最小副本和最大副本 来设置自动缩放范围。
- 指定每个工作节点的CPU和内存资源(默认:4 vCPU,8 GB)。
- 添加GPU 资源以启用 GPU 加速(目前仅支持 NVIDIA GPU)。
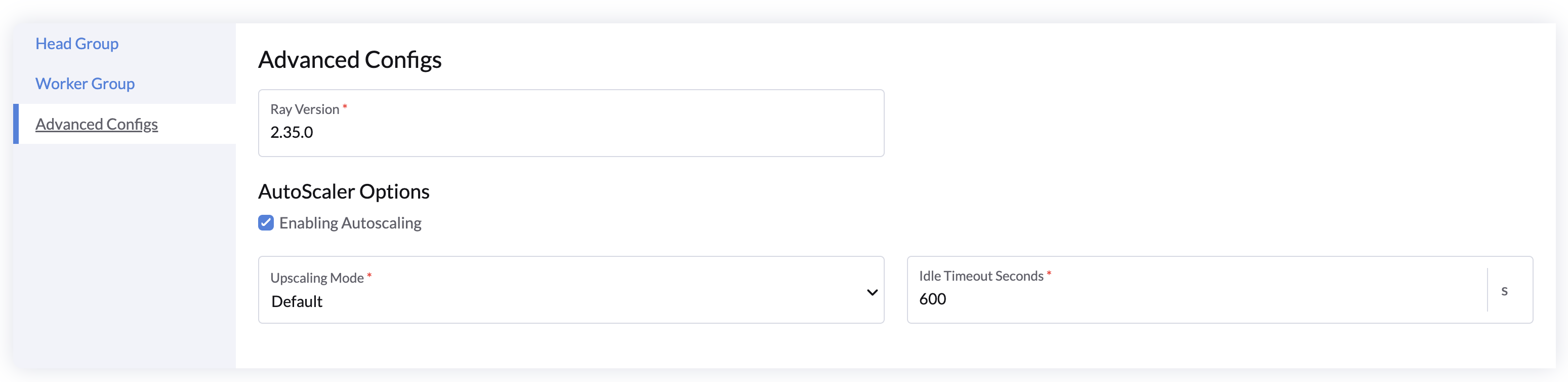
高级配置
- 配置 Ray 版本,如果您想使用特定的 Ray 版本。
- 自动缩放选项:
- 勾选 启用自动缩放 以启用或禁用工作组的自动缩放。
- 指定 空闲超时(以秒为单位),当没有任务运行时自动缩放工作节点到最小副本。
用户指南
集群创建后,您可以使用 Ray 客户端连接到集群并在大规模上运行机器学习工作负载。
设置 Ray 客户端
首先,转到您的 Python 项目并通过以下命令安装 Ray 客户端:
pip install -U "ray"
如有需要,请查看 Ray 安装指南,获取有关安装 Ray 的更多详细信息。
提交 Ray 作业
要运行 Ray 作业,我们还需要能够向 Ray 集群发送 HTTP 请求。�让我们从一个可以在本地运行的示例脚本开始。以下脚本使用 Ray API 提交一个任务并打印其返回值:
# script.py
import ray
@ray.remote
def hello_world():
return "hello world"
ray.init()
print(ray.get(hello_world.remote()))
在本地运行该脚本以验证其是否有效:
python script.py
2024-09-28 22:46:21,735 INFO worker.py:1777 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
hello world
现在让我们使用 Python SDK 提交作业到远程机器学习集群。
LLMOS API 令牌可以通过 API Keys 页面获得
# ray-job.py
from ray.job_submission import JobSubmissionClient, JobStatus
import time
client = JobSubmissionClient(
address="https://localhost:8005/api/v1/namespaces/default/services/http:ml-cluster1-head-svc:dashboard/proxy/", # 用您的 ML 集群的端点 URL 替换此 URL
headers={"Authorization": "Bearer llmos-qcmqf:xxxxxxxxxxxxxxp4bgq"}, # 用您的 LLMOS API 令牌替换
verify=False # 禁用 SSL 验证或使用自定义 CA 证书
)
job_id = client.submit_job(
# 执行的入口 shell 命令
entrypoint="python script.py",
# 包含 script.py 文件的本地目录路径
runtime_env={"working_dir": "./"}
)
print(job_id)
def wait_until_status(job_id, status_to_wait_for, timeout_seconds=5):
start = time.time()
while time.time() - start <= timeout_seconds:
status = client.get_job_status(job_id)
print(f"status: {status}")
if status in status_to_wait_for:
break
time.sleep(1)
wait_until_status(job_id, {JobStatus.SUCCEEDED, JobStatus.STOPPED, JobStatus.FAILED})
logs = client.get_job_logs(job_id)
print(logs)
JobSubmissionClient 将作业提交到 Ray 集群并返回作业 ID。可以使用作业 ID 检查作业的状态并检索其日志。
python rayjob.py
2024-09-28 22:57:49,615 INFO dashboard_sdk.py:338 -- Uploading package gcs://_ray_pkg_aee80db9018e46d7.zip.
2024-09-28 22:57:49,615 INFO packaging.py:531 -- Creating a file package for local directory './'.
raysubmit_5XExd25xnNqfYSYK
status: PENDING
status: RUNNING
status: RUNNING
status: SUCCEEDED
2024-09-28 07:58:30,120 INFO job_manager.py:527 -- Runtime env is setting up.
2024-09-28 07:58:31,288 INFO worker.py:1458 -- Using address 10.42.0.223:6379 set in the environment variable RAY_ADDRESS
2024-09-28 07:58:31,289 INFO worker.py:1598 -- Connecting to existing Ray cluster at address: 10.42.0.223:6379...
2024-09-28 07:58:31,301 INFO worker.py:1774 -- Connected to Ray cluster. View the dashboard at 10.42.0.223:8265
hello world
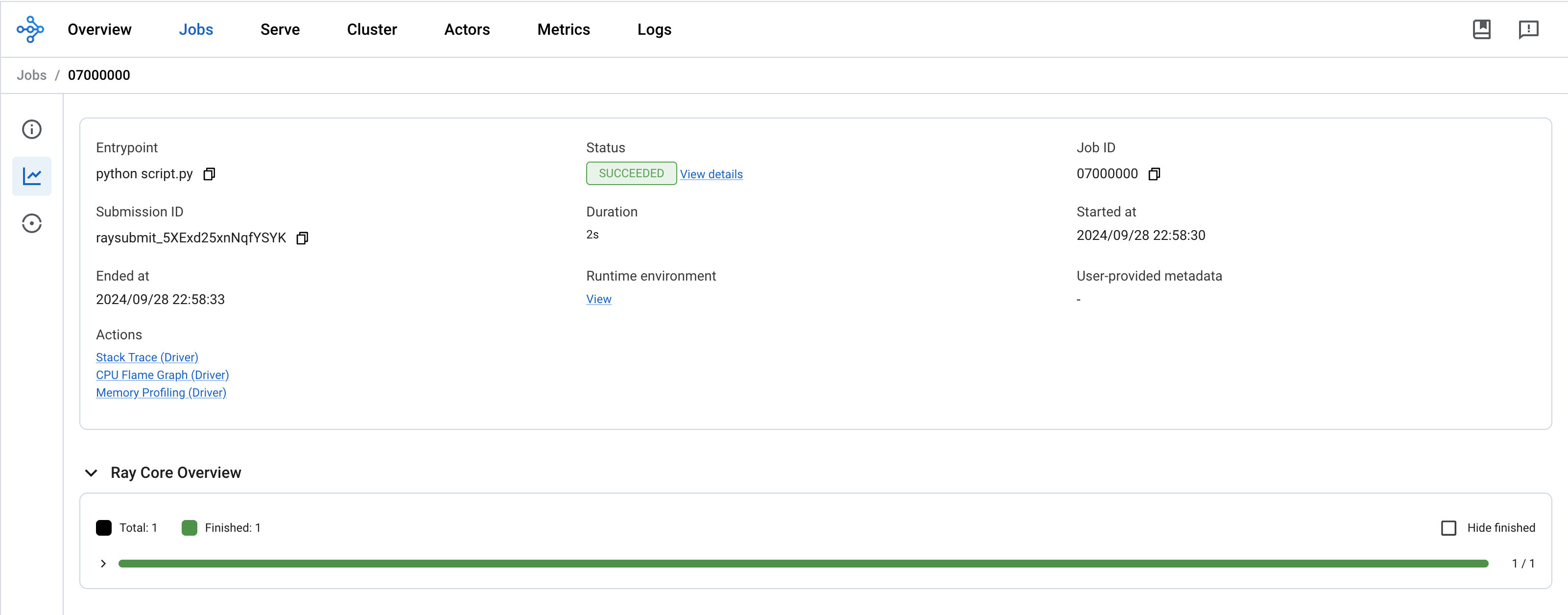
您还可以在 ML 集群仪表板中检查作业状态和日志。
更多示例
在上面,我们展示了如何向远程 ML 集群提交简单作业。您还可以利用 Ray AI 库运行更高级的端到端 ML 工作流。以下是一些参考示例: