启用监控
LLMOS Monitoring 通过预配置的 Grafana 仪表盘、Prometheus 规则和告警规则等功能,使集群和 GPU 指标的监控变得简单、易用。这一功能主要基于 Prometheus Operator 开发集成。
本页面将介绍如何配置与管理内置的 LLMOS Monitoring。
启用监控
要启用监控功能,管理员用户需访问 Cluster Tools 页面。点击 Install 后,您将被引导至 Monitoring 配置页面。
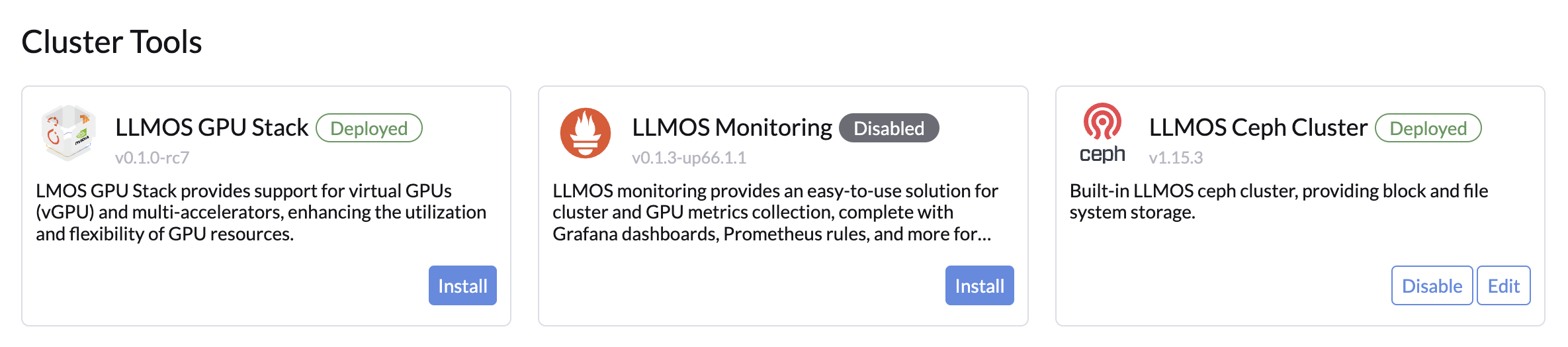
前置要求
- 如果您的集群是多节点集群并且需要为监控功能启用持久存储,请先启用 Ceph 系统存储,然后再设置监控。
- 确保您的集群满足以下资源需求:
- CPU:至少
1250m - 内存:至少
1210Mi - 存储:至少
50Gi - 详情请参考 资源限制与请求。
- CPU:至少
Prometheus 设置
- Admin API:启用 Prometheus Admin API,以使用快照和删除时间序列等高级功能。默认关闭。
- 抓取间隔:Prometheus 收集指标的频率。默认值:
30s。 - 评估间隔:Prometheus 检查告警规则的频率。默认值:
30s。 - 数据保留时间:指标保留的时长。默认值:
10d。 - 保留大小:存储指标的最大大小。默认值:
50GiB。 - 资源:为 Prometheus Pod 设置资源请求和限制。
- 持久存储:若需在部署和升级期间保留数据,为 Prometheus 配置持久存储。
- 推荐至少
50Gi。
- 推荐至少
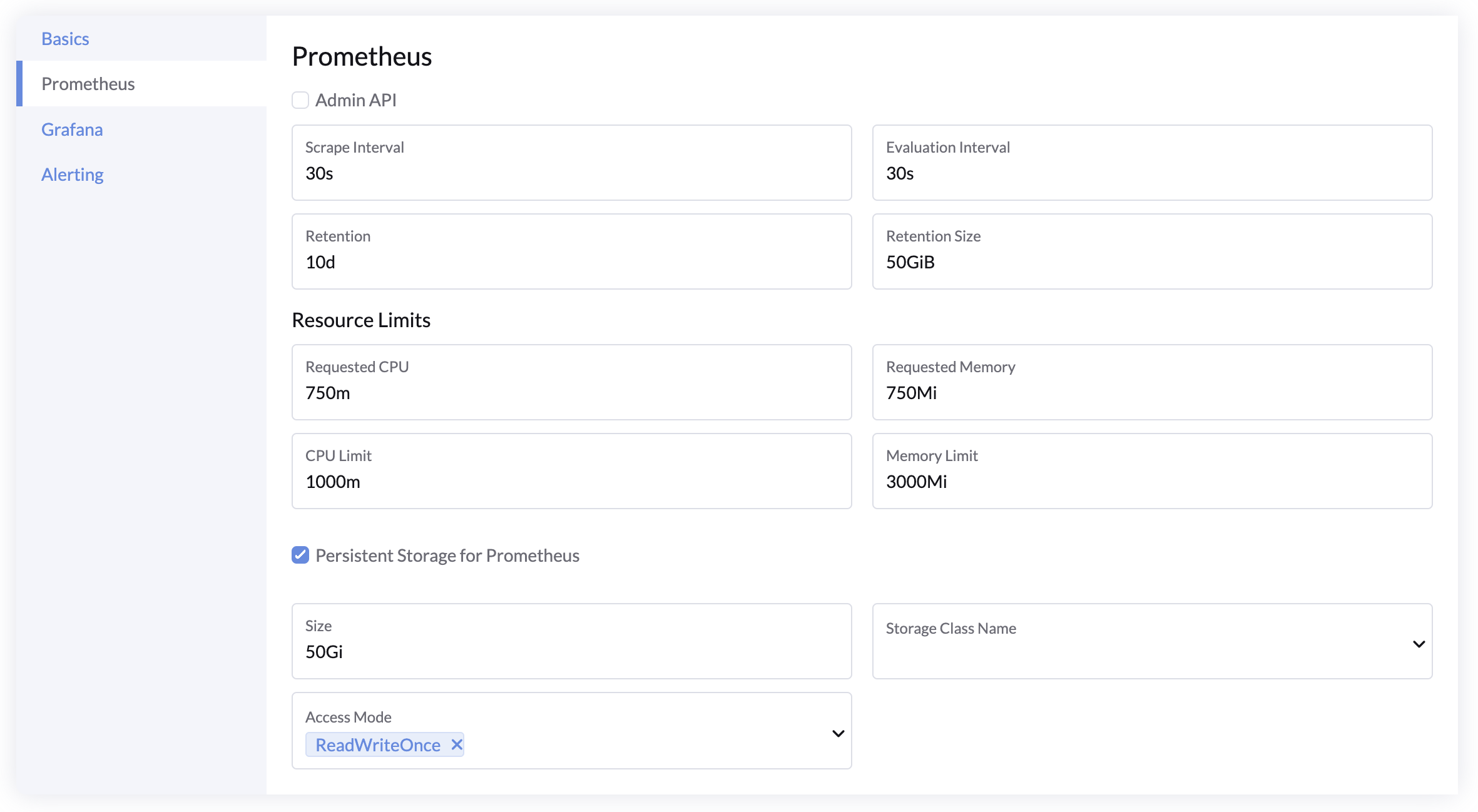
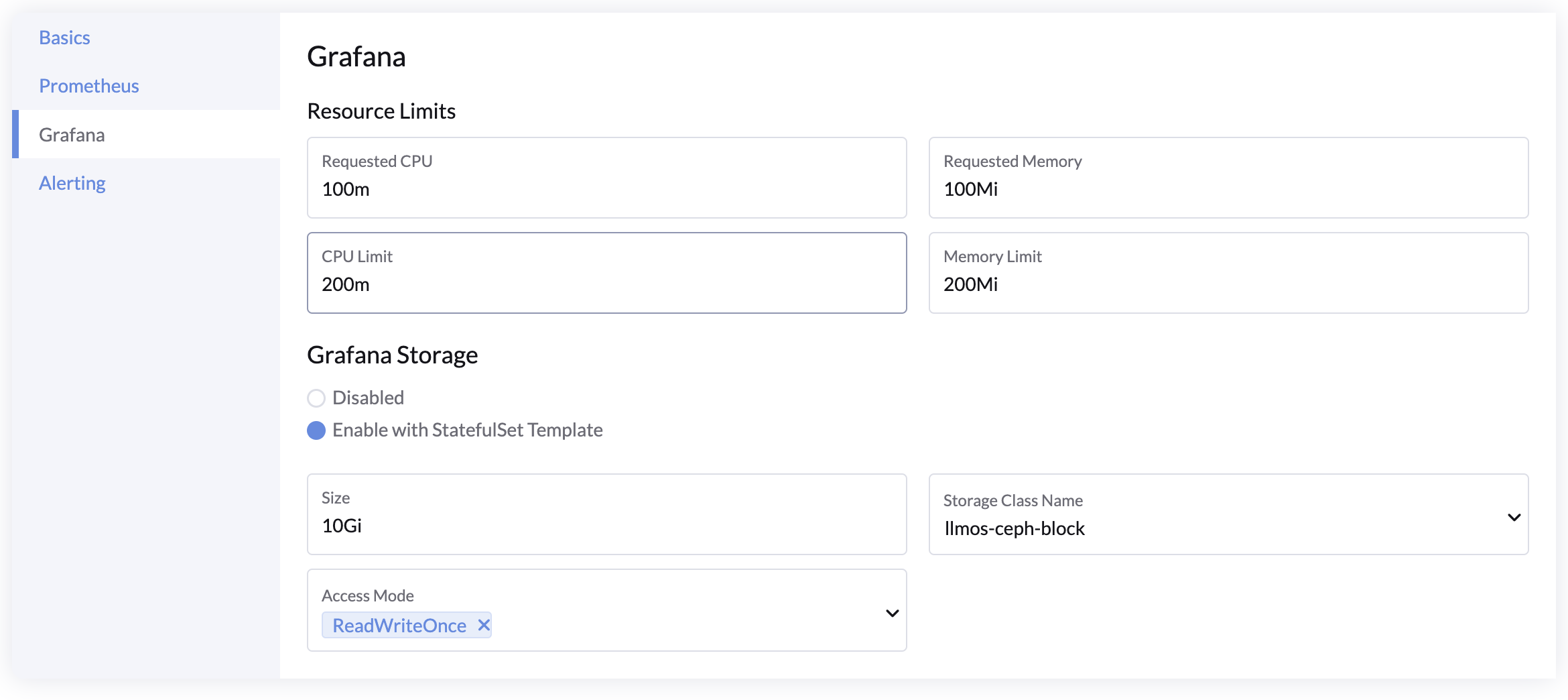
Grafana 设置
- 资源:为 Grafana Pod 设置资源请求和限制。
- 持久存储:配置存储以在升级或重新部署期间保留自定义仪表盘。
备注
LLMOS Monitoring 提供的默认仪表盘不依赖持久化存储且无法直接修改。
AlertManager 设置
- 启用 AlertManager:默认启用。

资源限制与请求
您可以在安装过程中调整资源请求和限制。下表显示了默认的最低要求:
| 组件 | CPU 请求 | 内存请求 | CPU 限制 | 内存限制 |
|---|---|---|---|---|
| prometheus-operator | 100m | 100Mi | 500m | 200Mi |
| prometheus | 750m | 750Mi | 1000m | 3000Mi |
| alertmanager | 100m | 100Mi | 1000m | 500Mi |
| grafana | 100m | 100Mi | 200m | 200Mi |
| kube-state-metrics | 100m | 130Mi | 200m | 200Mi |
| prometheus-node-exporter | 100m | 30Mi | 200m | 50Mi |
| 总计 | 1250m | 1210Mi | 3100m | 4150Mi |
持久存储:Prometheus 至少需要 50Gi 的存储空间。