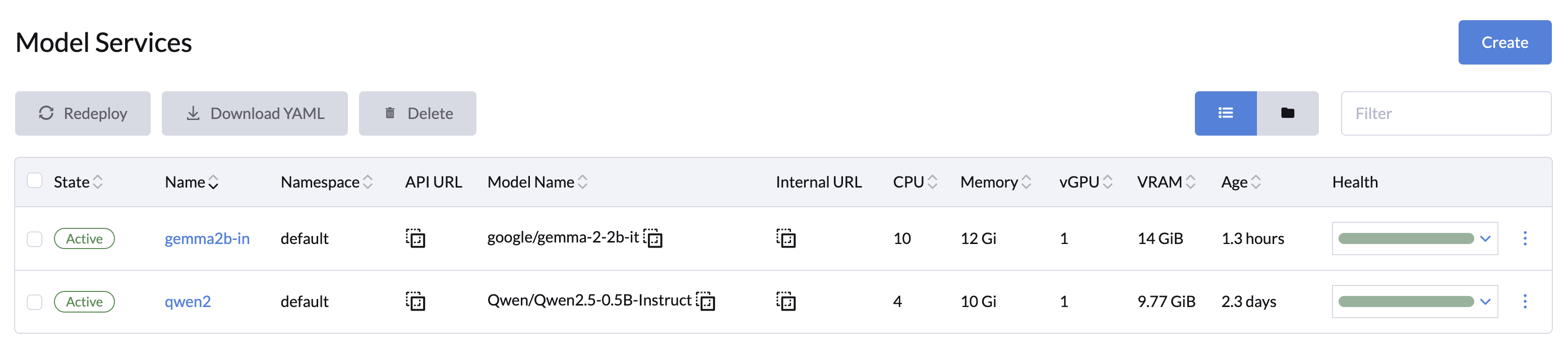
模型服务
LLMOS 平台通过 ModelService 简化了大语言模型(LLM)的部署, 为用户提供了简单,友好的配置和管理界面。推理服务利用强大的 vLLM 服务引擎。通过指定模型名称、Hugging Face 配置、资源要求等参数,用户可以轻松高效地设置和部署模型,并支持大规模运行。
创建模型服务
您可以通过 LLMOS 管理 > 模型服务 页面创建一个或多个模型服务。
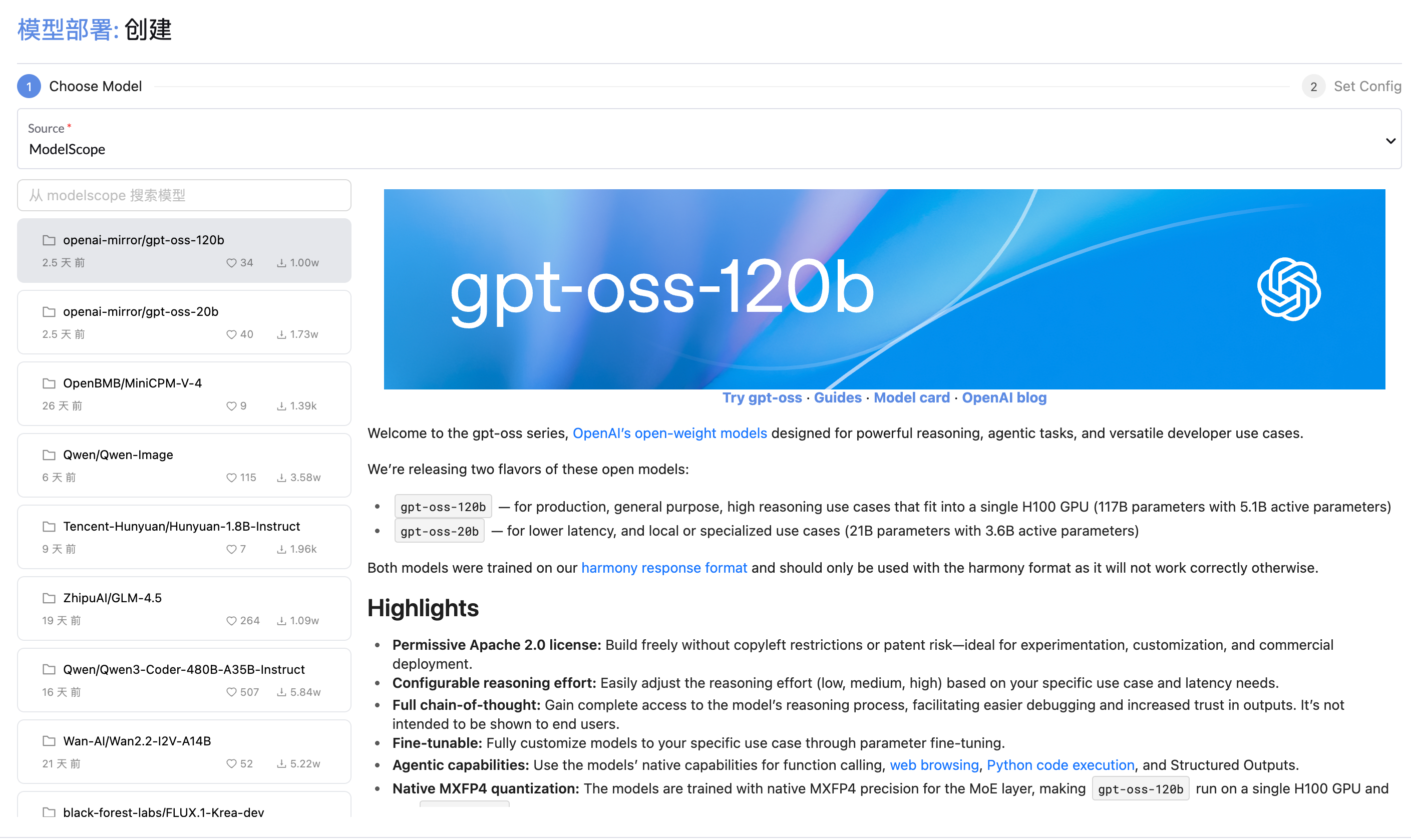
选择模型
从 huggingface、modelscope 或本地选择一个模型。如果您选择本地模型,它将显示本地模型。
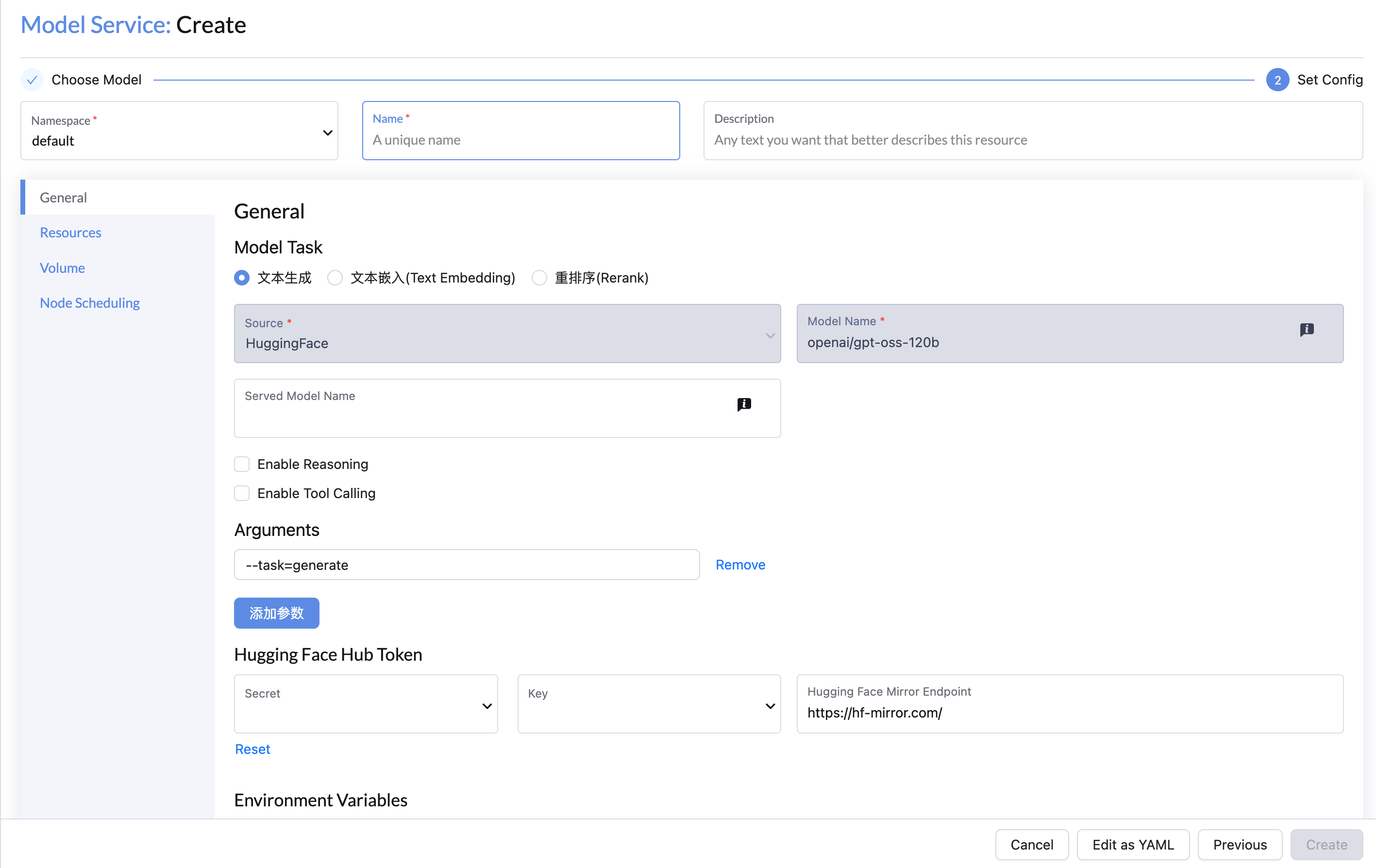
配置
通用配置
- 名称和命名空间:输入模型服务的名称和命名空间。
- 引擎参数(可选):如有需要,请在 参数 字段中添加参数,例如
--dtype=half --max-model-len=4096。更多详情。 - Hugging Face 配置(可选):
- 对于需要身份验证的模型,可以使用密钥凭证。
- 如需使用代理,可以添加自定义的 Hugging Face 镜像 URL(例如,
https://hf-mirror.com/)。
- 环境变量(可选):根据需要添加额外的环境变量, 更多详情。
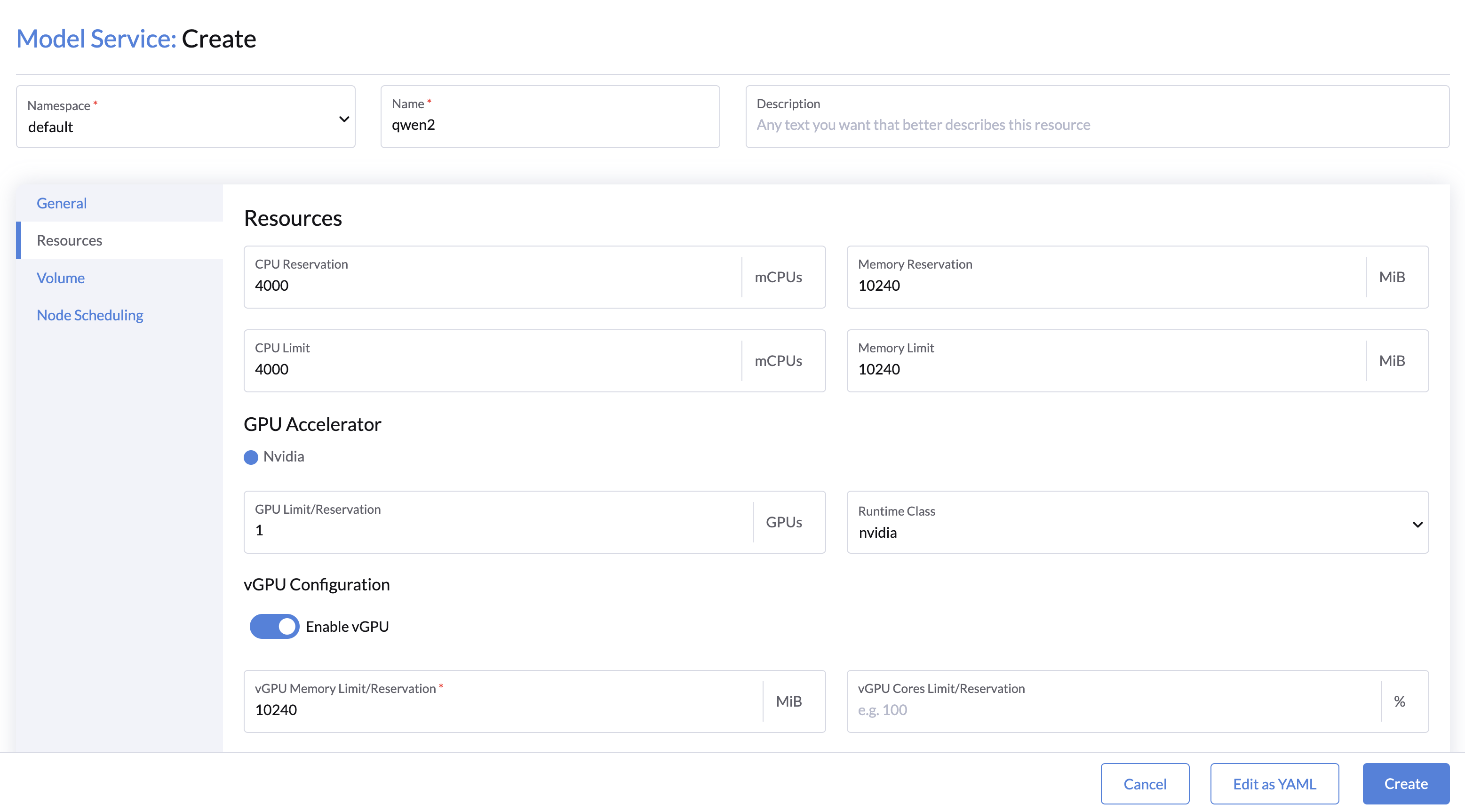
资源配置
有关大语言模型的 GPU 资源需求,请参阅 LLM numbers。
- CPU 和内存:为模型分配 CPU 和内存资源。
- GPU 资源:
- 选择 GPU 和 Runtime Class(默认:nvidia)。
- 最小值:最少使用 1 个 vGPU。
- 对于较大的大模型(例如 Llama3-70B),可使用张量并行来跨多个 GPU 资源进行分配。例如,使用4个 GPU 时,张量并行将被置大小为4。
- (对于小模型或测试场景)可使用共享 GPU 设备,请启用 vGPU 并指定
vGPU内存大小(以 MiB 为单位)和vGPU Cores(默认:100%)。
- 选择 GPU 和 Runtime Class(默认:nvidia)。
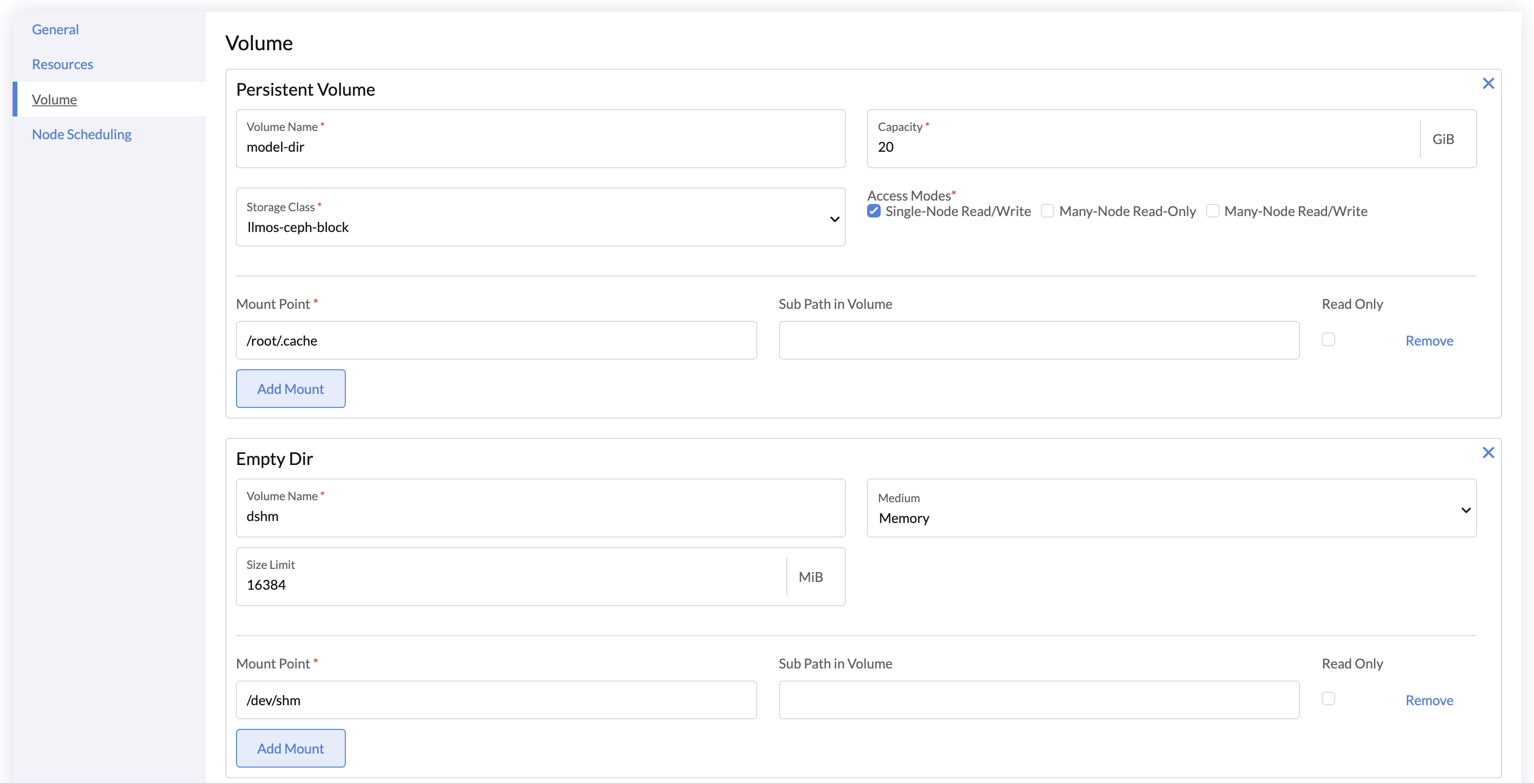
卷
- 持久卷:
- 默认:一个挂载到
/root/.cache的持久卷用于存储下载的模型。 - 对于跨服务共享模型,可以将默认卷替换为自定义的 Many-Node Read/Write 持久卷。
- 对于 本地路径 模型:
- 添加一个包含模型文件的现有卷,以�跳过下载过程。
- 如果不需要,可以移除默认的
model-dir卷。
- 默认:一个挂载到
- 共享内存(dshm):
- 将
emptyDir卷挂载到/dev/shm,并将 Medium 设置为 Memory,用于临时内存存储。 - 对于 PyTorch 张量并行推理,这是必要的,因其需要在进程之间共享内存。
- 如果未启用,共享内存的默认大小为 64 MiB。
- 将
节点调度
您可以为模型服务指定节点约束,使用节点标签,或者将其留空以在任何可用节点上运行。

有关节点调度的更多详情,请参考 Kubernetes 节点亲和力文档。
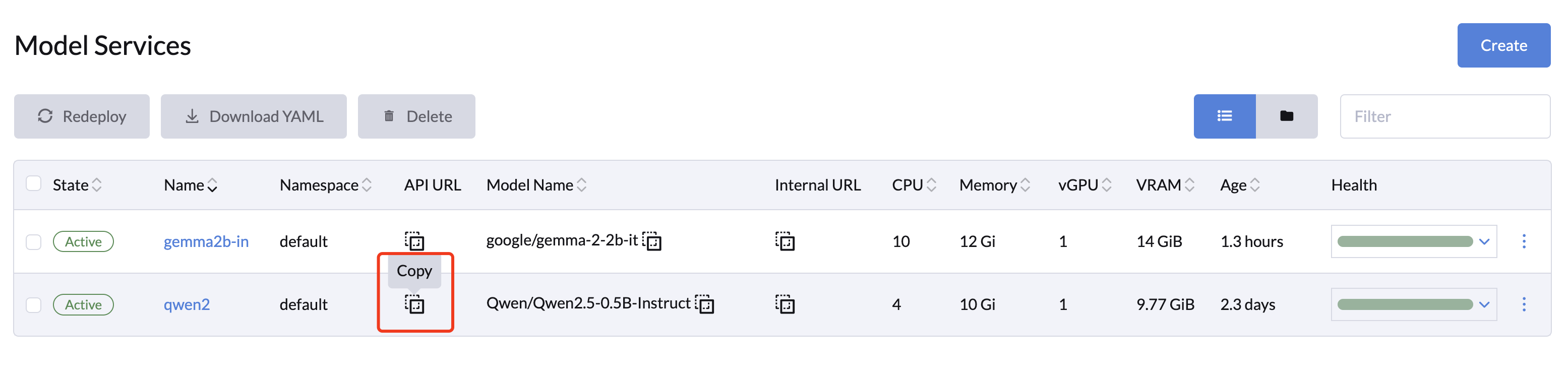
访问模型服务 API
模型服务在 /v1 路径下暴露了一系列与 OpenAI API 兼容的 RESTful API。您可以通过点击所选模型的 Copy 按钮获取模型 API URL。
API 端点
| 路由路径 | 方法 | 描述 |
|---|---|---|
/v1/chat/completions | POST | 使用模型服务执行多轮包含上下文的聊天对话。 |
/v1/completions | POST | 使用模型服务执行单次的标准输出。 |
/v1/embeddings | POST | 使用模型服务生成嵌入结果。 |
/v1/models | GET | 列出所有可用模型。 |
/health | GET | 检查模型服务 HTTP 服务器的健康状态。 |
/tokenize | POST | 使用正在运行的模型服务 Tokenize 文本。 |
/detokenize | POST | 使用正在运行的模型服务将标记反向转换。 |
/openapi.json | GET, HEAD | 获取模型服务的 OpenAPI JSON 规范。 |
API 使用示例
LLMOS API 令牌可以通过 API Keys 页面获得。
cURL 示例
export LLMOS_API_KEY=myapikey
export API_BASE=192.168.31.100:8443/api/v1/namespaces/default/services/modelservice-qwen2:http/proxy/v1
curl -k -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LLMOS_API_KEY" \
-d '{
"model": "Qwen/Qwen2.5-0.5B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Say this is a test"
}
],
"temperature": 0.9
}' \
$API_BASE/chat/completions
响应示例:
{
"id":"chat-efffa70236bd4edda7e5420349339d45",
"object":"chat.completion",
"created":1727267645,
"model":"Qwen/Qwen2.5-0.5B-Instruct",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"Yes, it is a test."
},
"logprobs":null,
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":24,
"total_tokens":32,
"completion_tokens":8
}
}
Python 示例
由于模型服务的 API 与 OpenAI 兼容,您可以将其作为基于 OpenAI 应用程序的直接替代品使用。
from openai import OpenAI
import httpx
# 设置 API 密钥和基本 URL
openai_api_key = "llmos-5frck:xxxxxxxxxg79c9p5"
openai_api_base = "https://192.168.31.100:8443/api/v1/namespaces/default/services/modelservice-qwen2:http/proxy/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
http_client=httpx.Client(verify=False), # 禁用 SSL 验证或使用自定义 CA 包。
)
completion = client.chat.completions.create(
model="Qwen/Qwen2.5-0.5B-Instruct",
messages=[{"role": "user", "content": "How do I output all files in a directory using Python?"}]
)
print(completion.choices[0].message.content)
Notebooks 交互
您还可以使用 Notebooks 与模型服务交互,Notebooks 可提供更丰富的 HTML、图形等更互动地探索模型的能力(例如,下面的 Jupyter Notebook)。

在您的 LLMOS 集群内,您可以使用模型服务的内部 DNS 名称来连接模型服务从而降低延迟和减少证书的配置。
要获取内部 DNS 名称,请点击模型服务的 Copy Internal URL 按钮。
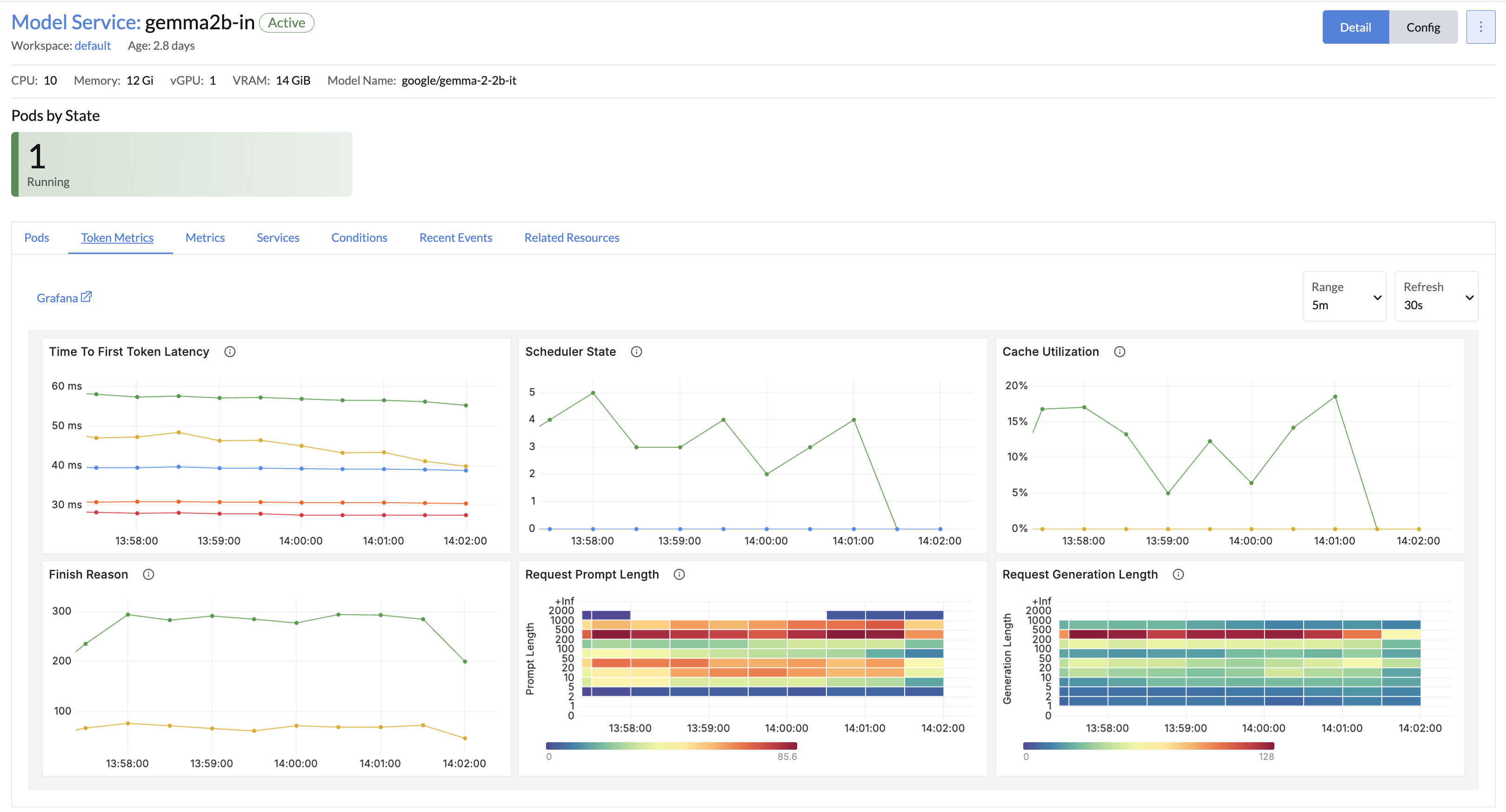
模型服务监控
模型服务默认与 LLMOS 监控 进行了集成并内置相应的监控指标,用于跟踪模型性能和使用情况等。
- 点击模型服务名称以打开其详细信息页面。
- 使用 Token 指标 查看 token 相关的监控指标。
- 使用 监控指标 标签查看服务 CPU、内存、磁盘 I/O 等资源使用情况。
添加 Hugging Face Token
在 Hugging Face 中某些模型需要身份验证才能下载。如果您的模型需要令牌,请按照以下步骤添加 Hugging Face 令牌:
- 转到 高级 > 密钥 并点击 创建。
- 选择 Opaque 密钥类型。

- 选择与模型服务匹配的 命名空间,并提供清晰��的 名称(例如,
my-hf-token)。 - 将 Key 设置为
token,并将 Hugging Face 令牌粘贴为 Value。

- 点击 创建 保存密钥。
创建后,密钥将作为选项显示,在同一命名空间中设置模型服务时可以选择该密钥。