启用 GPU Stack
LLMOS GPU Stack 是一个 GPU 管理工具集,它为 LLMOS 平台带来了虚拟 GPU (vGPU) 和多加速器支持,提升了 GPU 资源的使用效率和灵活性。
本指南提供了 GPU Stack 架构、组件及基本配置的快速概览。
备注
LLMOS GPU Stack 将始终启用,因为它是平台的核心组件。

信息
当前支持的 GPU: ✅ Nvidia CUDA
未来计划支持:
- AMD ROCm
- 昇腾 CANN
- 寒武纪 MLU
- 海光 DCU
前提条件
为确保 GPU Stack 正常工作,确保你的节点满足以下要求:
- Nvidia 驱动程序:在具有 GPU 设备的节点上安装 Nvidia 驱动程序。请参阅 Nvidia GPU 驱动安装指南。
- GPU 必须具有 CUDA 计算能力 7.5 或更高版本。
GPU Stack 组件
当 GPU Stack 启用时,以下组件会安装在 llmos-gpu-stack-system 命名空间中:
- Nvidia GPU Operator:管理 Nvidia GPU 资源。了解更多。
- GPU Device Plugin:一个 DaemonSet,暴露并管理 GPU 设备。了解更多。
- GPU Device Manager:一个 Deployment,管理 LLMOS GPU 自定义资源定义 (CRD)。
- Volcano 调度器:用于批量和群组调度带有 GPU 资源的工作负载的插件。了解更多。
配置
GPU Operator
- 启用 NVIDIA GPU Operator:默认启用 Nvidia GPU Operator 以管理 Nvidia GPU 设备。
- vGPU 数量:设置每个 GPU 可以创建的最大 vGPU 实例数。默认值:
10。

设备管理器
- 资源设置:配置 GPU 设备管理器 Pod 的资源请求和限制。

状态与监控
当 LLMOS GPU Stack 被标记为 Deployed 后:
- 检查
llmos-gpu-stack-system命名空间中 GPU Stack 组件的状态。 - 确保 GPU 管理 中的
Nvidia Cluster Policies标记为Ready。
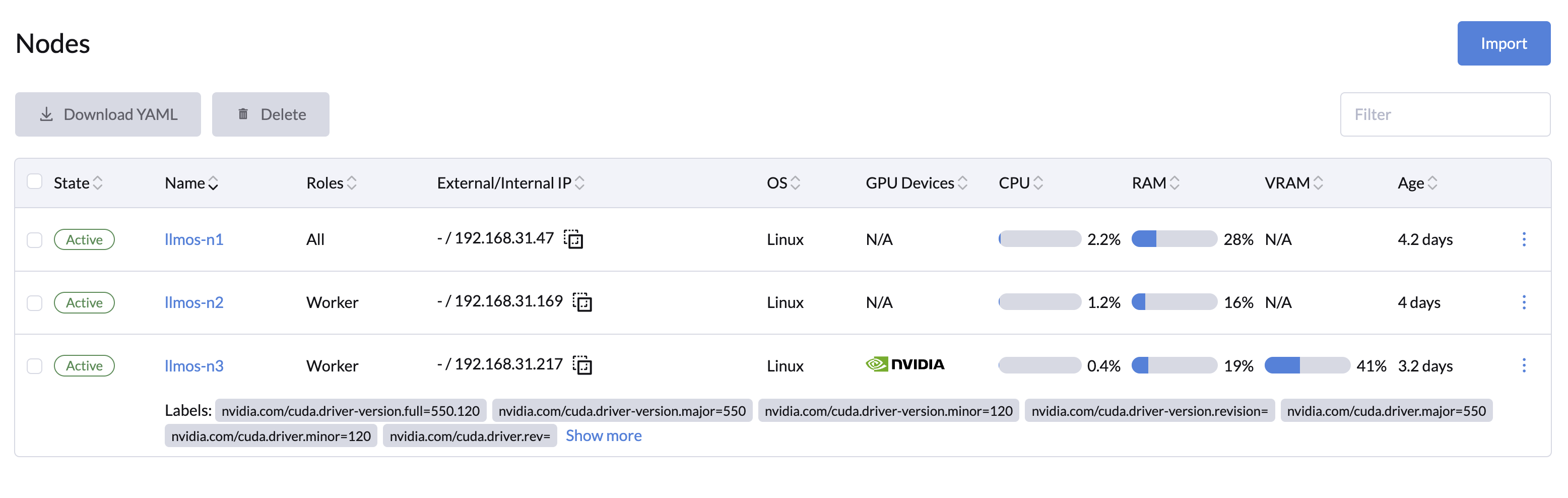
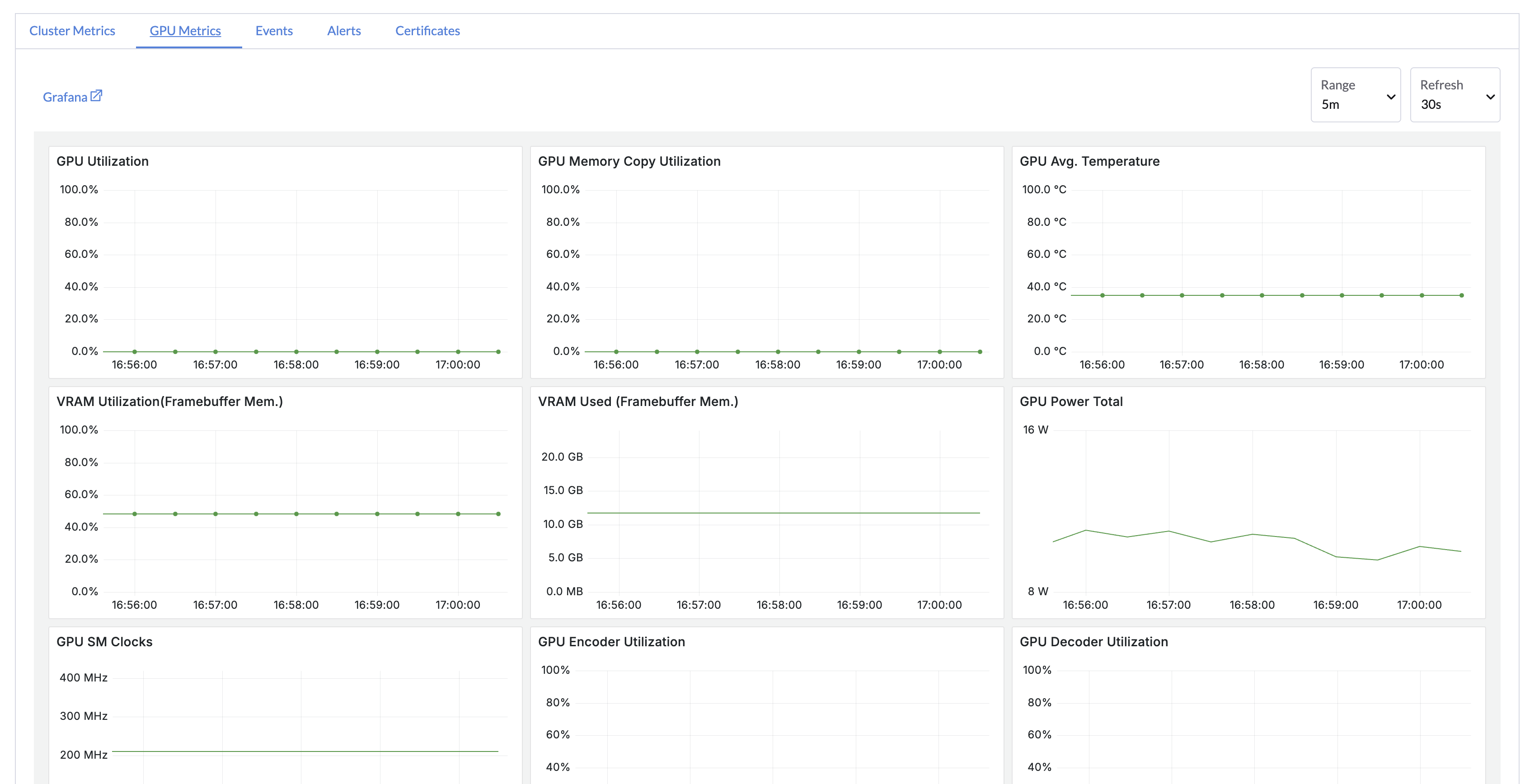
在仪表板中,您可以通过以下方式监控 GPU 使用情况和状态: