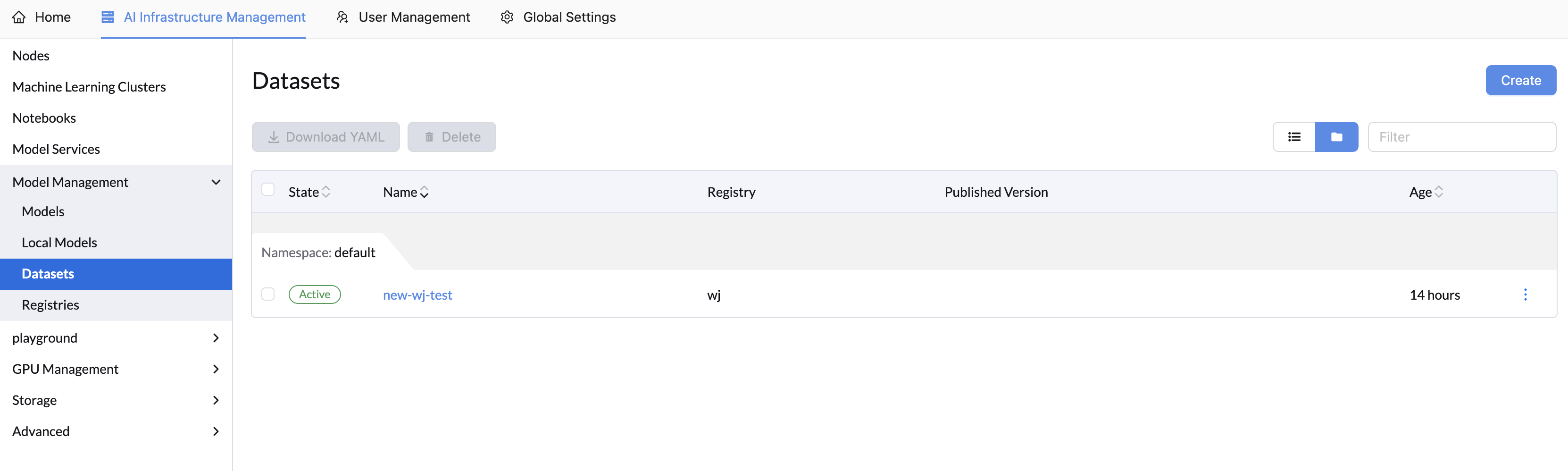
Datasets
The LLMOS platform provides comprehensive dataset management capabilities, allowing you to store, organize, and manage machine learning datasets in registries. Datasets support multi-version management, file operations, and can be published for use in notebooks and other applications.
Overview
Datasets in LLMOS serve as a centralized way to manage your machine learning data assets. You can:
- Store Datasets in Registries: Upload and organize dataset files in private registries
- Multi-Version Management: Maintain different versions of your datasets with full lifecycle control
- File Management: View, upload, and download dataset files with an intuitive interface
- Publishing: Publish dataset versions to make them immutable and ready for production use
- Notebook Integration: Mount published datasets directly in Notebooks for data analysis
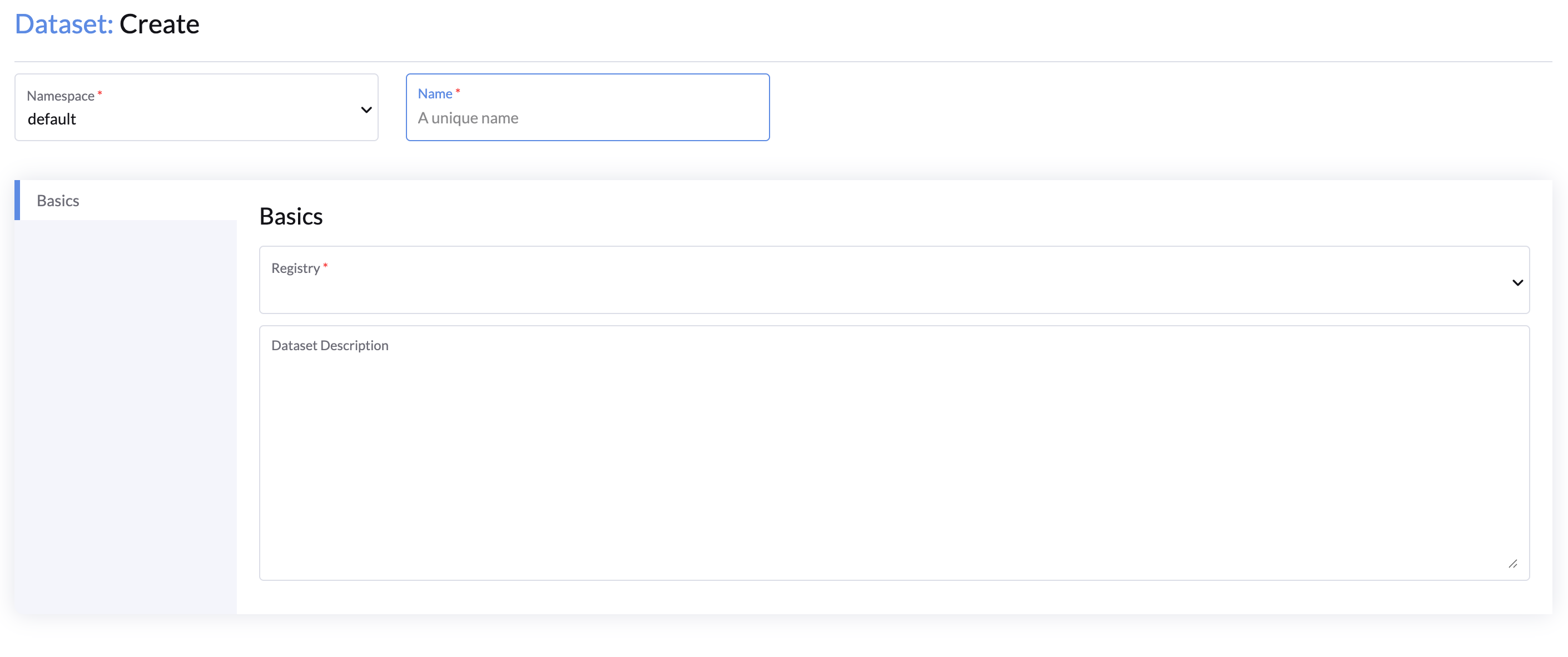
Creating a Dataset
You can create datasets from the AI Infrastructure Management > Model Management > Datasets page.
General Configuration
- Namespace: Choose the namespace for the dataset.
- Name: Enter a unique name for your dataset.
- Registry: Select the registry where the dataset will be stored.
- Dataset Description: Provide a description that better describes this dataset.
Managing Dataset Files
Once a dataset is created, you can manage its files through the dataset details page.
File Operations
The dataset file management interface provides several operations:
- View Files: Browse the dataset's file structure and contents
- Upload Files: Add new files to the dataset version
- Download Files: Download individual files or entire folders
- Create Folders: Organize files in a hierarchical structure
- Remove Files: Delete unnecessary files
- Publish: Make the dataset version immutable and ready for production use

Dataset Versioning
LLMOS provides robust version management for datasets, allowing you to track changes and maintain data lineage across different iterations of your data.
Version Lifecycle
Each dataset version goes through the following states:
- Draft: Editable version where you can add, modify, or remove files
- Published: Immutable version that cannot be modified, ready for production use
Creating New Versions
When creating a new dataset version, you have two data inheritance options:
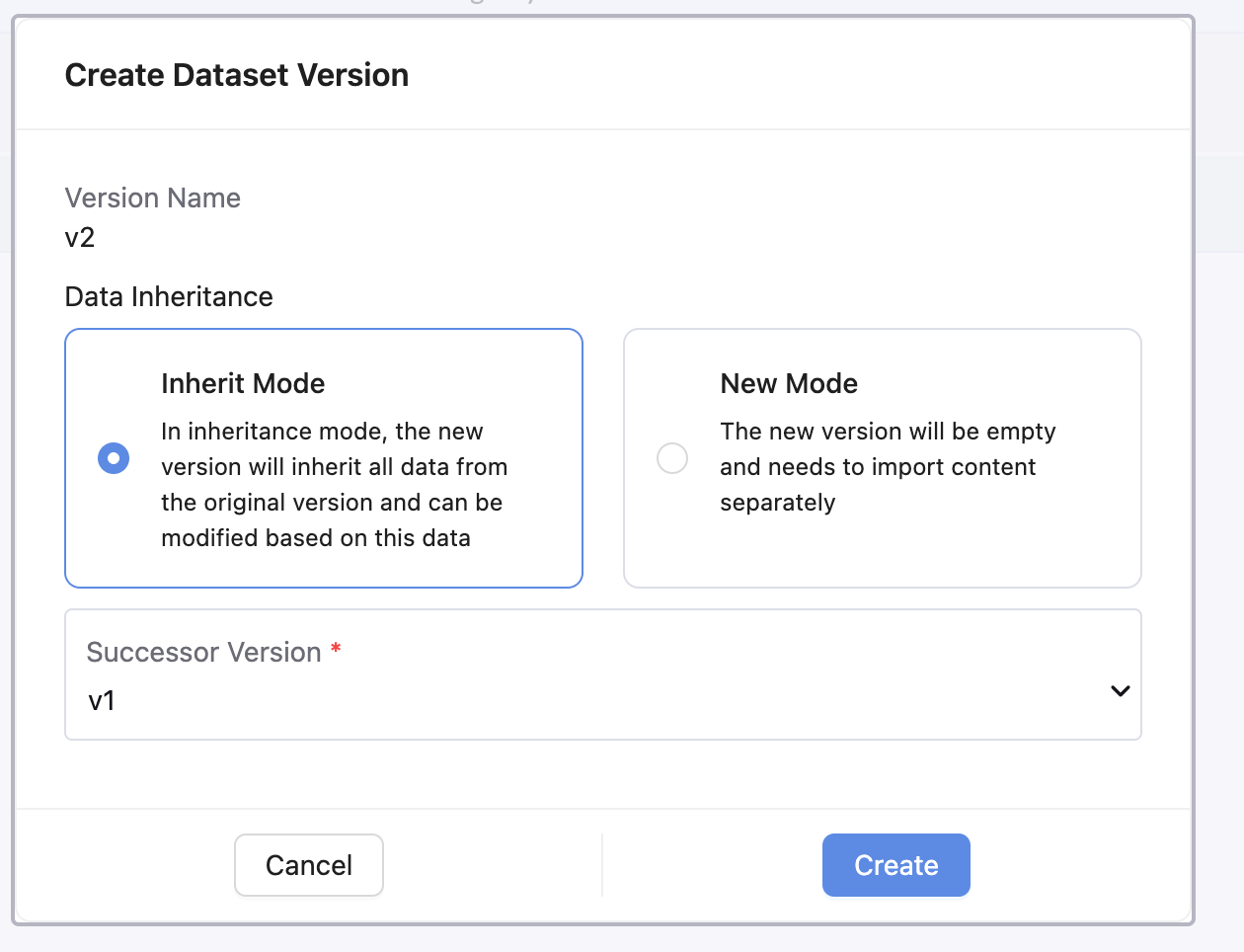
Inherit Mode
In inheritance mode, the new version will inherit all data from the original version and can be modified based on this data. This is useful when:
- Making incremental updates to existing datasets
- Adding new files while keeping existing ones
- Modifying or removing specific files from a previous version
- Creating variations of existing datasets
New Mode
The new version will be empty and needs to import content separately. This is ideal when:
- Creating completely different datasets with the same name structure
- Starting fresh with new data sources
- Building datasets from scratch for different use cases
Publishing Datasets
Publishing is a key feature that makes dataset versions immutable and ready for production use.
Prerequisites
Ceph Storage Requirement
Dataset publishing functionality depends on Ceph Storage. You must enable and configure Ceph Storage before publishing datasets.
Publishing Process
- Navigate to the dataset version you want to publish
- Ensure all required files are uploaded and organized
- Click Publish in the dataset files interface and waiting it published
- The version becomes immutable and ready for use
Published Dataset Benefits
- Immutability: Published versions cannot be modified, ensuring data consistency
- Notebook Integration: Can be mounted directly in notebooks for analysis
- Production Ready: Suitable for training and inference workflows
- Data Lineage: Clear tracking of dataset versions used in experiments
Integration with Notebooks
Published datasets can be seamlessly integrated with Notebooks for data analysis and machine learning workflows.